Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Was ist das Language Server-Protokoll?
Die Unterstützung von umfangreichen Bearbeitungsfeatures wie automatischen Abschluss von Quellcode oder Go to Definition für eine Programmiersprache in einem Editor oder einer IDE ist traditionell sehr schwierig und zeitaufwändig. In der Regel muss ein Domänenmodell (ein Scanner, ein Parser, eine Typprüfung, ein Generator und mehr) in der Programmiersprache des Editors oder der IDE geschrieben werden. Beispielsweise wird das Eclipse CDT-Plug-In, das Unterstützung für C/C++ in der Eclipse IDE bietet, in Java geschrieben, da die Eclipse IDE selbst in Java geschrieben wird. Nach diesem Ansatz würde es bedeuten, ein C/C++-Domänenmodell in TypeScript für Visual Studio Code und ein separates Domänenmodell in C# für Visual Studio zu implementieren.
Das Erstellen sprachspezifischer Domänenmodelle ist auch viel einfacher, wenn ein Entwicklungstool vorhandene sprachspezifische Bibliotheken wiederverwenden kann. Diese Bibliotheken werden jedoch in der Regel in der Programmiersprache selbst implementiert (z. B. werden gute C/C++-Domänenmodelle in C/C++ implementiert). Die Integration einer C/C++-Bibliothek in einen in TypeScript geschriebenen Editor ist technisch möglich, aber schwierig.
Sprachserver
Ein weiterer Ansatz besteht darin, die Bibliothek in einem eigenen Prozess auszuführen und prozessübergreifende Kommunikation zu verwenden, um mit der Bibliothek zu sprechen. Die gesendeten Nachrichten bilden ein Protokoll. Das Sprachserverprotokoll (Language Server Protocol, LSP) ist das Produkt der Standardisierung der zwischen einem Entwicklungstool und einem Sprachserverprozess ausgetauschten Nachrichten. Die Verwendung von Sprachservern oder Dämonen ist keine neue oder neuartige Idee. Editoren wie Vim und Emacs haben dies seit einiger Zeit getan, um semantische Unterstützung für die automatische Vervollständigung bereitzustellen. Ziel des LSP war es, diese Arten von Integrationen zu vereinfachen und ein nützliches Framework für die Bereitstellung von Sprachfeatures für eine Vielzahl von Tools bereitzustellen.
Ein gemeinsames Protokoll ermöglicht die Integration von Programmiersprachenfeatures in ein Entwicklungstool mit minimalem Aufwand, indem eine vorhandene Implementierung des Domänenmodells der Sprache verwendet wird. Ein Sprachserver-Back-End könnte in PHP, Python oder Java geschrieben werden, und der LSP lässt es leicht in eine Vielzahl von Tools integrieren. Das Protokoll funktioniert auf einer allgemeinen Abstraktionsebene, sodass ein Tool umfangreiche Sprachdienste anbieten kann, ohne die Nuancen, die für das zugrunde liegende Domänenmodell spezifisch sind, vollständig zu verstehen.
Wie die Arbeit am LSP gestartet wurde
Der LSP hat sich im Laufe der Zeit weiterentwickelt und ist heute auf Version 3.0. Es begann, als das Konzept eines Sprachservers von OmniSharp aufgenommen wurde, um umfangreiche Bearbeitungsfunktionen für C# bereitzustellen. Zunächst verwendete OmniSharp das HTTP-Protokoll mit einer JSON-Nutzlast und wurde in mehrere Editoren integriert, einschließlich Visual Studio Code.
Zur gleichen Zeit begann Microsoft mit der Arbeit an einem TypeScript-Sprachserver, mit der Idee, TypeScript in Editoren wie Emacs und Sublime Text zu unterstützen. In dieser Implementierung kommuniziert ein Editor über stdin/stdout mit dem TypeScript-Serverprozess und verwendet eine JSON-Nutzlast, die vom V8-Debuggerprotokoll für Anforderungen und Antworten inspiriert wurde. Der TypeScript-Server wurde in das TypeScript Sublime-Plug-In und VS Code für die umfassende TypeScript-Bearbeitung integriert.
Nachdem sie zwei verschiedene Sprachserver integriert haben, begann das VS Code-Team mit der Erkundung eines Common Language Server-Protokolls für Editoren und IDEs. Ein gängiges Protokoll ermöglicht es einem Sprachanbieter, einen einzelnen Sprachserver zu erstellen, der von verschiedenen IDEs genutzt werden kann. Ein Sprachserver-Consumer muss nur einmal die Clientseite des Protokolls implementieren. Dies führt zu einer Win-Win-Situation sowohl für den Sprachanbieter als auch für den Sprachverbraucher.
Das Sprachserverprotokoll begann mit dem vom TypeScript-Server verwendeten Protokoll und erweitert es mit weiteren Sprachfeatures, die von der VS Code-Sprach-API inspiriert wurden. Das Protokoll wird aufgrund seiner Einfachheit und vorhandenen Bibliotheken mit JSON-RPC für Remoteaufrufe gesichert.
Das VS Code-Team hat das Protokoll prototypisch umgesetzt, indem es mehrere Lint-Sprachserver implementierte, die auf Anforderungen reagieren, eine Datei zu durchsuchen, und eine Reihe erkannter Warnungen und Fehler zurückgeben. Ziel war es, eine Datei zu linieren, während der Benutzer in einem Dokument bearbeitet, was bedeutet, dass während einer Editorsitzung viele Lintinganforderungen vorhanden sind. Es war sinnvoll, einen Server in Betrieb zu halten, damit ein neuer Lintingprozess nicht für jede Benutzeränderung gestartet werden muss. Mehrere linter-Server wurden implementiert, darunter die ESLint- und TSLint-Erweiterungen von VS Code. Diese beiden Linter-Server werden sowohl in TypeScript/JavaScript implementiert als auch auf Node.jsausgeführt. Sie teilen eine Bibliothek, die den Client- und Serverteil des Protokolls implementiert.
Funktionsweise des LSP
Ein Sprachserver wird in einem eigenen Prozess ausgeführt, und Tools wie Visual Studio oder VS Code kommunizieren mit dem Server mithilfe des Sprachprotokolls über JSON-RPC. Ein weiterer Vorteil des Sprachservers, der in einem dedizierten Prozess ausgeführt wird, besteht darin, dass Leistungsprobleme im Zusammenhang mit einem einzelnen Prozessmodell vermieden werden. Der tatsächliche Transportkanal kann entweder Stdio, Sockets, named pipes oder Node IPC sein, wenn sowohl der Client als auch der Server in Node.jsgeschrieben werden.
Im Folgenden finden Sie ein Beispiel dafür, wie ein Tool und ein Sprachserver während einer Routinebearbeitungssitzung kommunizieren:

Der Benutzer öffnet eine Datei (als Dokument bezeichnet) im Tool: Das Tool benachrichtigt den Sprachserver, dass ein Dokument geöffnet ist ('textDocument/didOpen'). Von nun an befindet sich die Wahrheit über den Inhalt des Dokuments nicht mehr auf dem Dateisystem, sondern wird vom Tool im Arbeitsspeicher gehalten.
Der Benutzer nimmt Änderungen vor: Das Tool benachrichtigt den Server über die Dokumentänderung ('textDocument/didChange'), und die semantischen Informationen des Programms werden vom Sprachserver aktualisiert. In diesem Fall analysiert der Sprachserver diese Informationen und benachrichtigt das Tool mit den erkannten Fehlern und Warnungen ('textDocument/publishDiagnostics').
Der Benutzer führt "Gehe zu Definition" für ein Symbol im Editor aus: Das Tool sendet eine 'textDocument/Definition'-Anforderung mit zwei Parametern: (1) den Dokument-URI und (2) die Textposition, an der die Anforderung "Gehe zu Definition" an den Server initiiert wurde. Der Server antwortet mit dem Dokument-URI und der Position der Definition des Symbols innerhalb des Dokuments.
Der Benutzer schließt das Dokument (Datei): Eine 'textDocument/didClose'-Benachrichtigung wird vom Tool gesendet und informiert den Sprachserver darüber, dass sich das Dokument jetzt nicht mehr im Arbeitsspeicher befindet und dass der aktuelle Inhalt jetzt auf dem neuesten Stand im Dateisystem ist.
In diesem Beispiel wird veranschaulicht, wie das Protokoll mit dem Sprachserver auf der Ebene der Editorfeatures wie "Gehe zu Definition" kommuniziert, "Alle Verweise suchen". Die vom Protokoll verwendeten Datentypen sind Editor- oder IDE-Datentypen wie das aktuell geöffnete Textdokument und die Position des Cursors. Die Datentypen befinden sich nicht auf der Ebene eines Programmiersprachendomänenmodells, das normalerweise abstrakte Syntaxbäume und Compilersymbole (z.B. aufgelöste Typen, Namespaces...) bereitstellen würde. Dies vereinfacht das Protokoll erheblich.
Sehen wir uns nun die Anforderung "textDocument/definition" genauer an. Nachfolgend finden Sie die Datenpakete, die zwischen dem Client-Tool und dem Sprachserver für die Anforderung "Go to Definition" in einem C++-Dokument ausgetauscht werden.
Dies ist die Anforderung:
{
"jsonrpc": "2.0",
"id" : 1,
"method": "textDocument/definition",
"params": {
"textDocument": {
"uri": "file:///p%3A/mseng/VSCode/Playgrounds/cpp/use.cpp"
},
"position": {
"line": 3,
"character": 12
}
}
}
Dies ist die Antwort:
{
"jsonrpc": "2.0",
"id": "1",
"result": {
"uri": "file:///p%3A/mseng/VSCode/Playgrounds/cpp/provide.cpp",
"range": {
"start": {
"line": 0,
"character": 4
},
"end": {
"line": 0,
"character": 11
}
}
}
}
Im Nachhinein ist die Beschreibung der Datentypen auf der Ebene des Editors und nicht auf der Ebene des Programmiersprachenmodells einer der Gründe für den Erfolg des Sprachserverprotokolls. Es ist viel einfacher, einen Textdokument-URI oder eine Cursorposition im Vergleich zur Standardisierung einer abstrakten Syntaxstruktur und Compilersymbole in verschiedenen Programmiersprachen zu standardisieren.
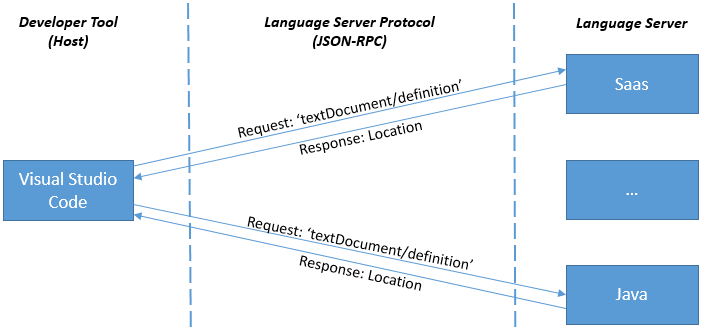
Wenn ein Benutzer mit verschiedenen Sprachen arbeitet, startet VS Code in der Regel einen Sprachserver für jede Programmiersprache. Das folgende Beispiel zeigt eine Sitzung, in der der Benutzer auf Java- und SASS-Dateien arbeitet.
Fähigkeiten
Nicht jeder Sprachserver kann alle vom Protokoll definierten Features unterstützen. Daher geben der Client und der Server ihre unterstützten Fähigkeiten als 'Capabilities' bekannt. Ein Server gibt beispielsweise an, dass er die Anforderung "textDocument/definition" verarbeiten kann, aber die Anforderung "arbeitsbereich/symbol" möglicherweise nicht verarbeitet. Ebenso können Clients mitteilen, dass sie Benachrichtigungen zum Speichern vor dem Speichern eines Dokuments bereitstellen können, sodass ein Server Textbearbeitungen berechnen kann, um das bearbeitete Dokument automatisch zu formatieren.
Integrieren eines Sprachservers
Die tatsächliche Integration eines Sprachservers in ein bestimmtes Tool wird nicht durch das Sprachserverprotokoll definiert und bleibt den Toolimplementierern überlassen. Einige Tools integrieren Sprachserver generisch, indem sie eine Erweiterung haben, die mit jeder Art von Sprachserver beginnen und kommunizieren kann. Andere wie VS Code erstellen eine benutzerdefinierte Erweiterung pro Sprachserver, sodass eine Erweiterung weiterhin einige benutzerdefinierte Sprachfeatures bereitstellen kann.
Zur Vereinfachung der Implementierung von Sprachservern und Clients gibt es Bibliotheken oder SDKs für die Client- und Serverteile. Diese Bibliotheken werden für verschiedene Sprachen bereitgestellt. Beispielsweise gibt es ein Sprachclient-npm-Modul , um die Integration eines Sprachservers in eine VS Code-Erweiterung und ein anderes Sprachserver-npm-Modul zu erleichtern, um einen Sprachserver mit Node.jszu schreiben. Dies ist die aktuelle Liste der Supportbibliotheken.
Verwenden des Language Server-Protokolls in Visual Studio
- Hinzufügen einer Language Server-Protokollerweiterung – Erfahren Sie, wie Sie einen Sprachserver in Visual Studio integrieren.