Nota
O acesso a esta página requer autorização. Podes tentar iniciar sessão ou mudar de diretório.
O acesso a esta página requer autorização. Podes tentar mudar de diretório.
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange tudo, desde a movimentação de dados até ciência de dados, análises em tempo real, business intelligence e relatórios. Saiba como iniciar uma nova avaliação gratuitamente!
Neste tutorial, vai criar uma fábrica de dados com a interface de utilizador (IU) do Azure Data Factory. O pipeline nesta fábrica de dados copia dados do armazenamento de Blob do Azure para um banco de dados no Banco de Dados SQL do Azure. O padrão de configuração neste tutorial aplica-se à cópia a partir de um arquivo de dados baseado em ficheiros para um arquivo de dados relacional. Para obter uma lista dos arquivos de dados suportados como origens e sinks, consulte a tabela de arquivos de dados suportados.
Nota
Se não estiver familiarizado com o Data Factory, veja Introdução ao Azure Data Factory.
Neste tutorial, vai executar os seguintes passos:
- Crie um data factory.
- Crie um pipeline com uma atividade de cópia.
- Testar a execução do pipeline.
- Acione o pipeline manualmente.
- Acione o pipeline em um cronograma.
- Monitorizar o pipeline e execuções de atividades.
- Desative ou exclua o gatilho agendado.
Pré-requisitos
- Subscrição do Azure. Se não tiver uma subscrição do Azure, crie uma conta do Azure gratuita antes de começar.
- Conta de armazenamento do Azure. Utilize o Armazenamento de blobs como um arquivo dos dados de origem. Se não tiver uma conta de armazenamento, veja Criar uma conta de armazenamento do Azure para seguir os passos para criar uma.
- Base de Dados SQL do Azure. Pode utilizar a base de dados como um arquivo de dados sink. Se você não tiver um banco de dados no Banco de Dados SQL do Azure, consulte Criar um banco de dados no Banco de Dados SQL do Azure para conhecer as etapas para criar um.
Criar um blob e uma tabela SQL
Agora, prepare o Armazenamento de blobs e a Base de Dados SQL para o tutorial, ao efetuar os seguintes passos.
Criar um blob de origem
Inicie o Bloco de Notas. Copie o seguinte texto e salve-o como um arquivo emp.txt :
FirstName,LastName John,Doe Jane,DoeMova esse arquivo para uma pasta chamada entrada.
Crie um contentor com o nome adftutorial no Armazenamento de blobs. Carregue sua pasta de entrada com o arquivo emp.txt para este contêiner. Você pode usar o portal do Azure ou ferramentas como o Gerenciador de Armazenamento do Azure para executar essas tarefas.
Criar uma tabela SQL sink
Use o seguinte script SQL para criar a tabela dbo.emp em seu banco de dados:
CREATE TABLE dbo.emp ( ID int IDENTITY(1,1) NOT NULL, FirstName varchar(50), LastName varchar(50) ) GO CREATE CLUSTERED INDEX IX_emp_ID ON dbo.emp (ID);Permita que os serviços do Azure acedam ao SQL Server. Certifique-se de que Permitir acesso aos serviços do Azure está ATIVADO para o SQL Server, para que o Data Factory possa escrever dados no SQL Server. Para verificar e ativar essa configuração, vá para o SQL Server no portal do Azure, selecione Rede de Segurança>> habilitar Redes> selecionadas marque Permitir que os serviços e recursos do Azure acessem este servidor em Exceções.
Criar uma fábrica de dados
Neste passo, vai criar uma fábrica de dados e iniciar a IU do Data Factory para criar um pipeline na fábrica de dados.
Abra o Microsoft Edge ou o Google Chrome. Atualmente, a IU do Data Factory é suportada apenas nos browsers Microsoft Edge e Google Chrome.
No menu à esquerda, selecione Criar um recurso>Analytics>Data Factory.
Na página Criar Data Factory, na guia Noções básicas, selecione a Assinatura do Azure na qual você deseja criar o data factory.
Em Grupo de Recursos, efetue um destes passos:
a) Selecione um grupo de recursos existente na lista suspensa.
b) Selecione Criar novo e insira o nome de um novo grupo de recursos.
Para saber mais sobre grupos de recursos, veja Utilizar grupos de recursos para gerir os recursos do Azure.
Em Região, selecione um local para o data factory. Seus armazenamentos de dados podem estar em uma região diferente do seu data factory, se necessário.
Em Nome, o nome da fábrica de dados do Azure deve ser globalmente exclusivo. Se receber uma mensagem de erro relacionada com o valor do nome, introduza um nome diferente para a fábrica de dados. (por exemplo, seunomeADFDemo). Para obter as regras de nomenclatura dos artefactos do Data Factory, veja Regras de nomenclatura do Data Factory.
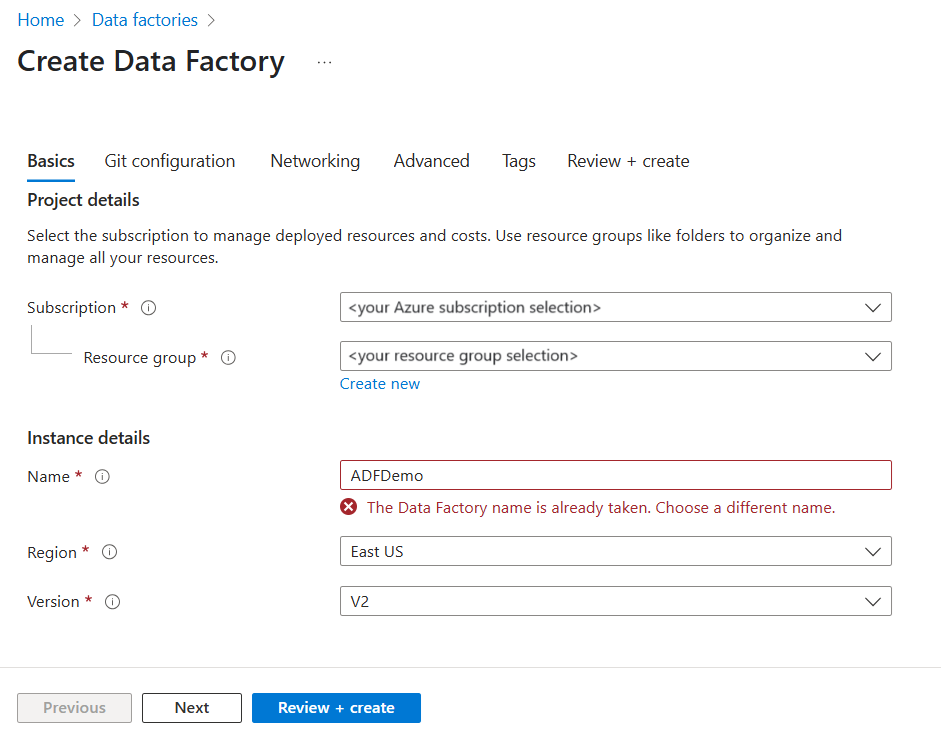
Em Versão, selecione V2.
Selecione a guia Configuração do Git na parte superior e marque a caixa de seleção Configurar o Git mais tarde .
Selecione Rever + criar e selecione Criar após a validação ser aprovada.
Após a conclusão da criação, você verá o aviso na Central de notificações. Selecione Ir para o recurso para navegar até a página Data factory.
Selecione Iniciar Studio no bloco Azure Data Factory Studio .
Criar um pipeline
Neste passo, vai criar um pipeline com uma atividade de cópia na fábrica de dados. A atividade de cópia copia os dados do Armazenamento de blobs para a Base de Dados SQL.
Na página inicial, selecione Orquestrar.
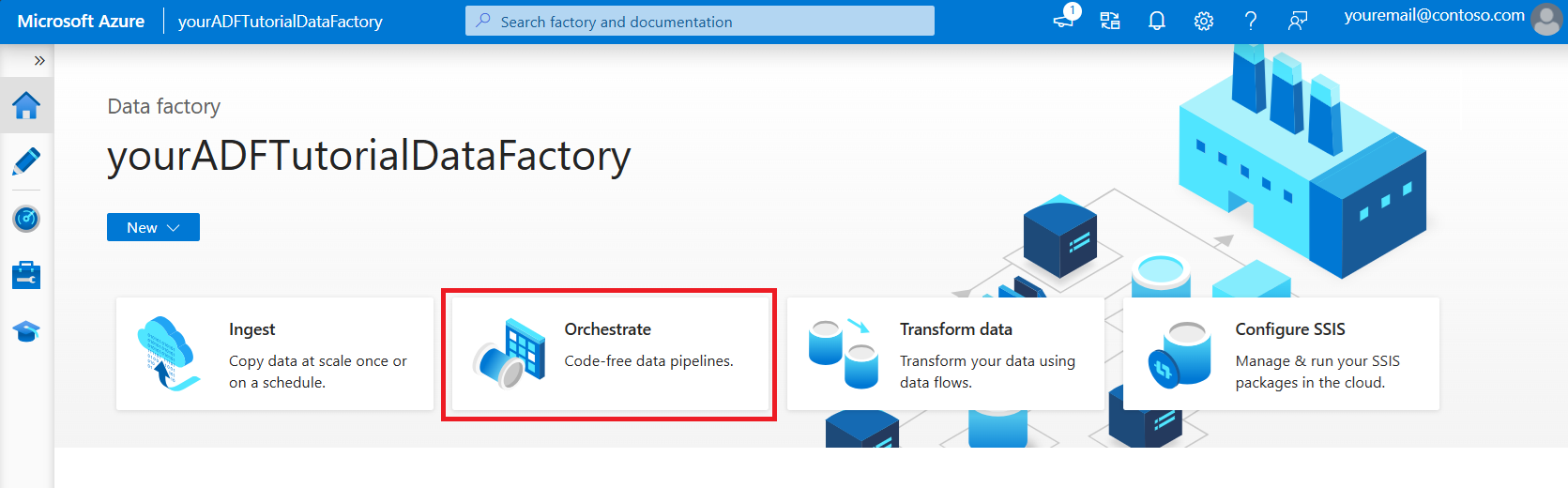
No painel Geral, em Propriedades, especifique CopyPipeline para Name. Em seguida, feche o painel clicando no ícone Propriedades no canto superior direito.
Na caixa de ferramentas Atividades, expanda a categoria Mover e Transformar e arraste e solte a atividade Copiar Dados da caixa de ferramentas para a superfície do designer de pipeline. Especifique CopyFromBlobToSql em Nome.

Configurar origem
Gorjeta
Neste tutorial, você usa a chave de conta como o tipo de autenticação para seu armazenamento de dados de origem, mas pode escolher outros métodos de autenticação suportados: URI SAS, Entidade de Serviço e Identidade Gerenciada , se necessário. Consulte as seções correspondentes neste artigo para obter detalhes. Para armazenar segredos para armazenamentos de dados com segurança, também é recomendável usar um Cofre de Chaves do Azure. Consulte este artigo para obter ilustrações detalhadas.
Selecione + Novo para criar um conjunto de dados de origem.
Na caixa de diálogo Novo Conjunto de Dados, selecione Armazenamento de Blob do Azure e, em seguida, selecione Continuar. A origem de dados está num Armazenamento de blobs, pelo que vai selecionar o Armazenamento de Blobs do Azure para o conjunto de dados de origem.
Na caixa de diálogo Selecionar Formato , escolha Texto Delimitado e selecione Continuar.
Na caixa de diálogo Definir Propriedades, digite SourceBlobDataset para Name. Marque a caixa de seleção Primeira linha como cabeçalho. Na caixa de texto Serviço vinculado, selecione + Novo.
Na caixa de diálogo Novo Serviço Vinculado (Armazenamento de Blobs do Azure), digite AzureStorageLinkedService como nome, selecione sua conta de armazenamento na lista Nome da conta de armazenamento. Testar conexão, selecione Criar para implantar o serviço vinculado.
Depois que o serviço vinculado é criado, ele é navegado de volta para a página Definir propriedades . Junto a Caminho do ficheiro, selecione Procurar.
Navegue até a pasta adftutorial/input, selecione o arquivo emp.txt e selecione OK.
Selecione OK. Ele navega automaticamente para a página do pipeline. Na guia Origem , confirme se SourceBlobDataset está selecionado. Para pré-visualizar os dados nesta página, selecione Pré-visualizar dados.

Configurar sink
Gorjeta
Neste tutorial, você usa a autenticação SQL como o tipo de autenticação para seu armazenamento de dados do coletor, mas pode escolher outros métodos de autenticação suportados: Service Principal e Managed Identity , se necessário. Consulte as seções correspondentes neste artigo para obter detalhes. Para armazenar segredos para armazenamentos de dados com segurança, também é recomendável usar um Cofre de Chaves do Azure. Consulte este artigo para obter ilustrações detalhadas.
Vá para o separador Sink e selecione + Novo para criar um conjunto de dados sink.
Na caixa de diálogo Novo Conjunto de Dados, insira "SQL" na caixa de pesquisa para filtrar os conectores, selecione Banco de Dados SQL do Azure e selecione Continuar.
Na caixa de diálogo Definir Propriedades, digite OutputSqlDataset para Name. Na lista suspensa Serviço vinculado, selecione + Novo. Os conjuntos de dados têm de estar associados a um serviço ligado. O serviço vinculado tem a cadeia de conexão que o Data Factory usa para se conectar ao Banco de Dados SQL em tempo de execução e especifica para onde os dados serão copiados.
Na caixa de diálogo Novo Serviço Vinculado (Banco de Dados SQL do Azure), execute as seguintes etapas:
a) Em Name, introduza AzureSqlDatabaseLinkedService.
b) Em Nome do servidor, selecione a sua instância do SQL Server.
c. Em Nome do banco de dados, selecione seu banco de dados.
d. Em Nome de utilizador, introduza o nome do utilizador.
e. Em Palavra-passe, introduza a palavra-passe do utilizador.
f. Selecione Testar ligação para testar a ligação.
g. Selecione Criar para implantar o serviço vinculado.

Ele navega automaticamente até a caixa de diálogo Definir propriedades . Em Tabela, selecione Enter manualmente e digite [dbo].[ emp]. Em seguida, selecione OK.
Vá para o separador com o pipeline e, em Conjunto de Dados Sink, confirme que OutputSqlDataset está selecionado.

Opcionalmente, você pode mapear o esquema da origem para o esquema de destino correspondente seguindo o mapeamento de esquema na atividade de cópia.
Validar o pipeline
Para validar o pipeline, selecione Validar na barra de ferramentas.
Você pode ver o código JSON associado ao pipeline clicando em Código no canto superior direito.
Debug and publish the pipeline (Depurar e publicar o pipeline)
Pode depurar um pipeline antes de publicar artefactos (serviços ligados, conjuntos de dados e pipeline) no Data Factory ou no seu próprio repositório Git do Azure.
Para depurar o pipeline, selecione Depurar na barra de ferramentas. Verá o estado da execução do pipeline no separador Saída, na parte inferior da janela.
Quando o pipeline puder ser executado com êxito, na barra de ferramentas superior, selecione Publicar tudo. Esta ação publica as entidades (conjuntos de dados e pipeline) que criou no Data Factory.
Aguarde até ver a mensagem de notificação Publicado com êxito . Para ver as mensagens de notificação, selecione Mostrar notificações no canto superior direito (botão de sino).
Acionar o pipeline manualmente
Neste passo, vai acionar manualmente o pipeline que publicou no passo anterior.
Selecione Adicionar gatilho na barra de ferramentas e, em seguida, selecione Disparar agora.
Na página Execução de pipeline, selecione OK.
Vá para o separador Monitorizar, no lado esquerdo. Verá uma execução de pipeline que é acionada por um acionador manual. Você pode usar links na coluna NOME DO PIPELINE para exibir detalhes da atividade e executar novamente o pipeline.

Para ver as execuções de atividade associadas à execução do pipeline, selecione o link CopyPipeline na coluna NOME DO PIPELINE. Neste exemplo, há apenas uma atividade, portanto, você vê apenas uma entrada na lista. Para obter detalhes sobre a operação de cópia, passe o mouse sobre a atividade e
selecione o link Detalhes (ícone de óculos) na coluna NOME DA ATIVIDADE . Selecione Todas as execuções de pipeline na parte superior para voltar à visualização Execuções de pipeline. Para atualizar a vista, selecione Atualizar.

Verifique se mais duas linhas foram adicionadas à tabela emp no banco de dados.

Acionar o pipeline com base numa agenda
Nesta agenda, vai criar um acionador de agenda para o pipeline. O acionador executa o pipeline na agenda especificada, como hora a hora ou diariamente. Aqui você define o gatilho para ser executado a cada minuto até a data final especificada.
Vá para o separador Criar, no lado esquerdo acima do separador do monitor.
Vá para o pipeline, selecione Gatilho na barra de ferramentas e selecione Novo/Editar.
Na caixa de diálogo Adicionar gatilhos , selecione Escolher gatilho e selecione + Novo.
Na janela Novo Acionador, siga os passos seguintes:
a) Em Nome, introduza RunEveryMinute.
b) Atualize a data de início do seu gatilho. Se a data for anterior à hora atual, o gatilho começará a entrar em vigor assim que a alteração for publicada.
c. Em Fuso horário, selecione a lista suspensa.
d. Defina a recorrência a cada 1 minuto(s).
e. Marque a caixa de seleção Especificar uma data de término e atualize a parte Terminar em para que fique alguns minutos após a data atual. O acionador só é ativado depois de publicar as alterações. Se você defini-lo com apenas alguns minutos de intervalo e não publicá-lo até lá, não verá uma execução de gatilho.
f. Para a opção Ativado , selecione Sim.
g. Selecione OK.
Importante
Está associado um custo a cada execução de pipeline, por isso, defina a data de fim adequadamente.
Na página Editar gatilho , reveja o aviso e, em seguida, selecione Guardar. O pipeline neste exemplo não tem nenhum parâmetro.
Selecione Publicar tudo para publicar a alteração.
Vá para o separador Monitorizar, do lado esquerdo, para ver as execuções do pipeline acionadas.

Para alternar da visualização Execuções de pipeline para a visualização Execuções de gatilho, selecione Execuções de gatilho no lado esquerdo da janela.
Verá as execuções do acionador numa lista.
Confirme que estão inseridas duas linhas por minuto (em cada execução do pipeline) na tabela emp até à hora de fim especificada.
Desativar gatilho
Para desativar o gatilho de cada minuto que você criou, siga estas etapas:
Selecione o painel Gerenciar no lado esquerdo.
Em Autor, selecione Triggers.
Passe o cursor sobre o gatilho RunEveryMinute que você criou.
- Selecione o botão Parar para desativar a execução do gatilho.
- Selecione o botão Excluir para desativar e excluir o gatilho.
Selecione Publicar tudo para salvar as alterações.
Conteúdos relacionados
O pipeline neste exemplo copia dados de uma localização para outra localização no Armazenamento de blobs. Aprendeu a:
- Criar uma fábrica de dados.
- Criar um pipeline com uma atividade de cópia.
- Testar a execução do pipeline.
- Acionar o pipeline manualmente.
- Acionar o pipeline com base numa agenda.
- Monitorizar o pipeline e execuções de atividades.
- Desative ou exclua o gatilho agendado.
Avance para o tutorial seguinte para saber como copiar dados do plano local para a cloud:
Para obter mais informações sobre como copiar dados de ou para o Armazenamento de Blobs do Azure e o Banco de Dados SQL do Azure, consulte estes guias de conectores: