Nota
O acesso a esta página requer autorização. Podes tentar iniciar sessão ou mudar de diretório.
O acesso a esta página requer autorização. Podes tentar mudar de diretório.
Este tutorial mostra como criar um modelo de classificação de aprendizado de máquina usando a scikit-learn biblioteca no Azure Databricks.
O objetivo é criar um modelo de classificação para prever se um vinho é considerado de "alta qualidade". O conjunto de dados consiste em 11 características de diferentes vinhos (por exemplo, teor alcoólico, acidez e açúcar residual) e uma classificação de qualidade entre 1 e 10.
Este exemplo também ilustra o uso do MLflow para acompanhar o processo de desenvolvimento do modelo e do Hyperopt para automatizar o ajuste de hiperparâmetros.
O conjunto de dados é do UCI Machine Learning Repository, apresentado em Modeling wine preferences by data mining from physicochemical properties [Cortez et al., 2009].
Antes de começar
- Seu espaço de trabalho deve estar habilitado para o Catálogo Unity. Consulte Introdução ao Catálogo Unity.
- Você deve ter permissão para criar um recurso de computação ou acesso a um recurso de computação que usa o Databricks Runtime for Machine Learning.
- Você deve ter o USE CATALOG privilégio em um catálogo.
- Dentro desse catálogo, você deve ter os seguintes privilégios em um esquema: USE SCHEMA, CREATE TABLEe CREATE MODEL.
Gorjeta
Todo o código neste artigo está disponível em um bloco de anotações que você pode importar diretamente para seu espaço de trabalho. Consulte Exemplo de bloco de anotações: Criar um modelo de classificação.
Etapa 1: Criar um bloco de anotações Databricks
Para criar um bloco de notas na sua área de trabalho, clique ![]() em Novo na barra lateral e, em seguida, clique em Bloco de Notas. Um bloco de anotações em branco é aberto no espaço de trabalho.
em Novo na barra lateral e, em seguida, clique em Bloco de Notas. Um bloco de anotações em branco é aberto no espaço de trabalho.
Para saber mais sobre como criar e gerir blocos de notas, consulte Gerir blocos de notas.
Etapa 2: Conectar-se a recursos de computação
Para fazer análise exploratória de dados e engenharia de dados, você deve ter acesso à computação. As etapas neste artigo exigem o Databricks Runtime for Machine Learning. Para obter mais informações e instruções para selecionar uma versão de ML do Databricks Runtime, consulte Databricks Runtime for Machine Learning.
No seu bloco de notas, clique no menu pendente Ligar no canto superior direito. Se você tiver acesso a um recurso existente que usa o Databricks Runtime for Machine Learning, selecione esse recurso no menu. Caso contrário, clique em Criar novo recurso... para configurar um novo recurso de computação.
Etapa 3: Configurar o registro, o catálogo e o esquema do modelo
Há duas etapas importantes necessárias antes de começar. Primeiro, você deve configurar o cliente MLflow para usar o Unity Catalog como o registro modelo. Introduza o seguinte código numa nova célula do seu bloco de notas.
import mlflow
mlflow.set_registry_uri("databricks-uc")
Você também deve definir o catálogo e o esquema onde o modelo será registrado. Você deve ter privilégio USE CATALOG no catálogo e privilégios USE SCHEMA, CREATE TABLE e CREATE MODEL no esquema.
Para obter mais informações sobre como usar o Unity Catalog, consulte O que é o Unity Catalog?.
Introduza o seguinte código numa nova célula do seu bloco de notas.
# If necessary, replace "main" and "default" with a catalog and schema for which you have the required permissions.
CATALOG_NAME = "main"
SCHEMA_NAME = "default"
Etapa 4: Carregar dados e criar tabelas do Unity Catalog
Este exemplo usa dois arquivos CSV disponíveis no databricks-datasets. Para saber como ingerir seus próprios dados, consulte Conectores padrão no Lakeflow Connect.
Introduza o seguinte código numa nova célula do seu bloco de notas. Este código faz o seguinte:
- Leia dados de
winequality-white.csvewinequality-red.csvpara o Spark DataFrames. - Limpe os dados substituindo espaços em nomes de colunas por sublinhados.
- Escreva os DataFrames nas tabelas
white_wineered_wineno Unity Catalog. Salvar os dados no Unity Catalog persiste os dados e permite controlar como compartilhá-los com outras pessoas.
white_wine = spark.read.csv("/databricks-datasets/wine-quality/winequality-white.csv", sep=';', header=True)
red_wine = spark.read.csv("/databricks-datasets/wine-quality/winequality-red.csv", sep=';', header=True)
# Remove the spaces from the column names
for c in white_wine.columns:
white_wine = white_wine.withColumnRenamed(c, c.replace(" ", "_"))
for c in red_wine.columns:
red_wine = red_wine.withColumnRenamed(c, c.replace(" ", "_"))
# Define table names
red_wine_table = f"{CATALOG_NAME}.{SCHEMA_NAME}.red_wine"
white_wine_table = f"{CATALOG_NAME}.{SCHEMA_NAME}.white_wine"
# Write to tables in Unity Catalog
spark.sql(f"DROP TABLE IF EXISTS {red_wine_table}")
spark.sql(f"DROP TABLE IF EXISTS {white_wine_table}")
white_wine.write.saveAsTable(f"{CATALOG_NAME}.{SCHEMA_NAME}.white_wine")
red_wine.write.saveAsTable(f"{CATALOG_NAME}.{SCHEMA_NAME}.red_wine")
Passo 5. Pré-processar e dividir os dados
Nesta etapa, você carrega os dados das tabelas do Unity Catalog criadas na Etapa 4 no Pandas DataFrames e pré-processa os dados. O código nesta seção faz o seguinte:
- Carrega os dados como Pandas DataFrames.
- Adiciona uma coluna booleana a cada DataFrame para distinguir vinhos tintos e brancos e, em seguida, combina os DataFrames em um novo DataFrame,
data_df. - O conjunto de dados inclui uma coluna
qualityque classifica os vinhos de 1 a 10, com 10 indicando a mais alta qualidade. O código transforma esta coluna em dois valores de classificação: "Verdadeiro" para indicar um vinho de alta qualidade (quality>= 7) e "Falso" para indicar um vinho que não é de alta qualidade (quality< 7). - Divide o DataFrame em conjuntos de dados de trem e teste separados.
Primeiro, importe as bibliotecas necessárias:
import numpy as np
import pandas as pd
import sklearn.datasets
import sklearn.metrics
import sklearn.model_selection
import sklearn.ensemble
import matplotlib.pyplot as plt
from hyperopt import fmin, tpe, hp, SparkTrials, Trials, STATUS_OK
from hyperopt.pyll import scope
Agora carregue e pré-processe os dados:
# Load data from Unity Catalog as Pandas dataframes
white_wine = spark.read.table(f"{CATALOG_NAME}.{SCHEMA_NAME}.white_wine").toPandas()
red_wine = spark.read.table(f"{CATALOG_NAME}.{SCHEMA_NAME}.red_wine").toPandas()
# Add Boolean fields for red and white wine
white_wine['is_red'] = 0.0
red_wine['is_red'] = 1.0
data_df = pd.concat([white_wine, red_wine], axis=0)
# Define classification labels based on the wine quality
data_labels = data_df['quality'].astype('int') >= 7
data_df = data_df.drop(['quality'], axis=1)
# Split 80/20 train-test
X_train, X_test, y_train, y_test = sklearn.model_selection.train_test_split(
data_df,
data_labels,
test_size=0.2,
random_state=1
)
Passo 6. Treinar o modelo de classificação
Esta etapa treina um classificador de aumento de gradiente usando as configurações padrão do algoritmo. Em seguida, ele aplica o modelo resultante ao conjunto de dados de teste e calcula, registra e exibe a área sob a curva de operação do recetor para avaliar o desempenho do modelo.
Primeiro, habilite o registro automático do MLflow:
mlflow.autolog()
Agora comece a corrida de treinamento modelo:
with mlflow.start_run(run_name='gradient_boost') as run:
model = sklearn.ensemble.GradientBoostingClassifier(random_state=0)
# Models, parameters, and training metrics are tracked automatically
model.fit(X_train, y_train)
predicted_probs = model.predict_proba(X_test)
roc_auc = sklearn.metrics.roc_auc_score(y_test, predicted_probs[:,1])
roc_curve = sklearn.metrics.RocCurveDisplay.from_estimator(model, X_test, y_test)
# Save the ROC curve plot to a file
roc_curve.figure_.savefig("roc_curve.png")
# The AUC score on test data is not automatically logged, so log it manually
mlflow.log_metric("test_auc", roc_auc)
# Log the ROC curve image file as an artifact
mlflow.log_artifact("roc_curve.png")
print("Test AUC of: {}".format(roc_auc))
Os resultados da célula mostram a área calculada sob a curva e um gráfico da curva ROC:
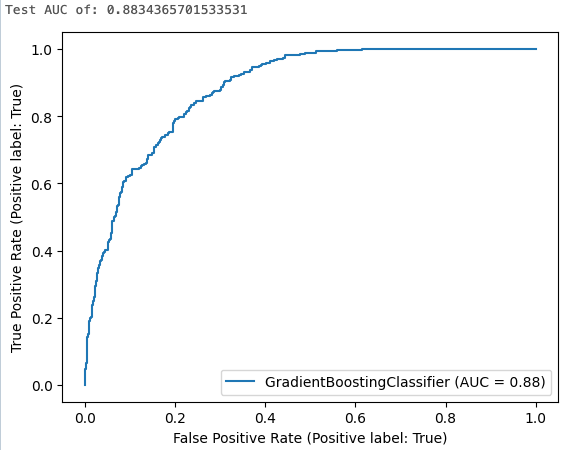
Passo 7. Exibir experimento executado no MLflow
O acompanhamento de experimentos MLflow ajuda você a acompanhar o desenvolvimento do modelo registrando o código e os resultados à medida que desenvolve modelos iterativamente.
Para visualizar os resultados registrados da execução de treinamento que você acabou de executar, clique no link na saída da célula, conforme mostrado na imagem a seguir.
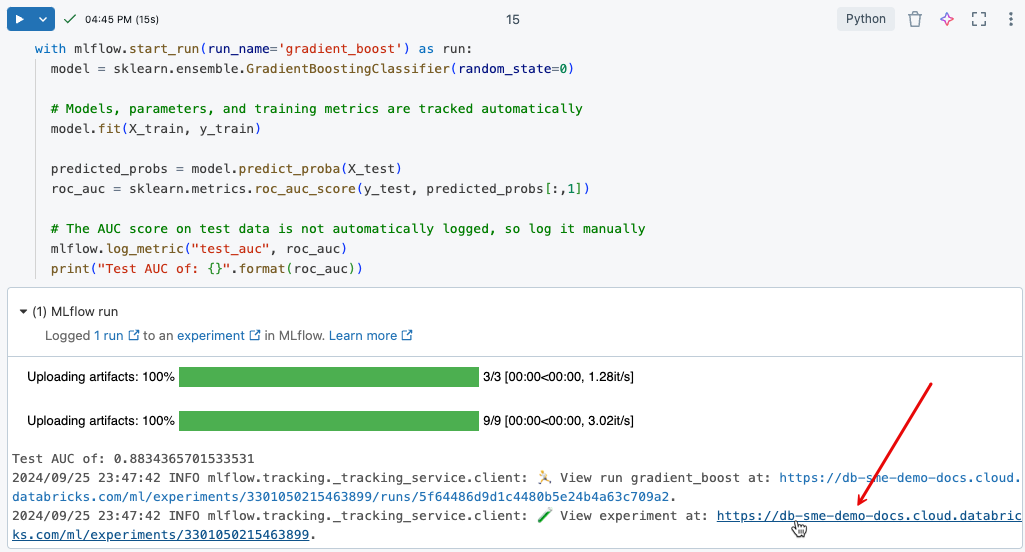
A página de experimento permite comparar execuções e visualizar detalhes de execuções específicas. Clique no nome de uma execução para ver detalhes como parâmetros e valores métricos para essa execução. Consulte Rastreamento de experimentos MLflow.
Você também pode visualizar as execuções de experimento do seu caderno clicando no ícone Experimento![]() no canto superior direito do caderno. Isso abre a barra lateral do experimento, que mostra um resumo de cada execução associada ao experimento do notebook, incluindo parâmetros e métricas de execução. Se necessário, clique no ícone de atualização para buscar e monitorar as execuções mais recentes.
no canto superior direito do caderno. Isso abre a barra lateral do experimento, que mostra um resumo de cada execução associada ao experimento do notebook, incluindo parâmetros e métricas de execução. Se necessário, clique no ícone de atualização para buscar e monitorar as execuções mais recentes.
![]()
Passo 8. Usar o Hyperopt para ajuste dos hiperparâmetros
Um passo importante no desenvolvimento de um modelo de ML é otimizar a precisão do modelo ajustando os parâmetros que controlam o algoritmo, chamados hiperparâmetros.
O Databricks Runtime ML inclui o Hyperopt, uma biblioteca Python para ajuste de hiperparâmetros. Você pode usar o Hyperopt para executar varreduras de hiperparâmetros e treinar vários modelos em paralelo, reduzindo o tempo necessário para otimizar o desempenho do modelo. O rastreamento MLflow é integrado ao Hyperopt para registrar automaticamente modelos e parâmetros. Para obter mais informações sobre como usar o Hyperopt no Databricks, consulte Ajuste de hiperparâmetros.
O código a seguir mostra um exemplo de uso do Hyperopt.
# Define the search space to explore
search_space = {
'n_estimators': scope.int(hp.quniform('n_estimators', 20, 1000, 1)),
'learning_rate': hp.loguniform('learning_rate', -3, 0),
'max_depth': scope.int(hp.quniform('max_depth', 2, 5, 1)),
}
def train_model(params):
# Enable autologging on each worker
mlflow.autolog()
with mlflow.start_run(nested=True):
model_hp = sklearn.ensemble.GradientBoostingClassifier(
random_state=0,
**params
)
model_hp.fit(X_train, y_train)
predicted_probs = model_hp.predict_proba(X_test)
# Tune based on the test AUC
# In production, you could use a separate validation set instead
roc_auc = sklearn.metrics.roc_auc_score(y_test, predicted_probs[:,1])
mlflow.log_metric('test_auc', roc_auc)
# Set the loss to -1*auc_score so fmin maximizes the auc_score
return {'status': STATUS_OK, 'loss': -1*roc_auc}
# SparkTrials distributes the tuning using Spark workers
# Greater parallelism speeds processing, but each hyperparameter trial has less information from other trials
# On smaller clusters try setting parallelism=2
spark_trials = SparkTrials(
parallelism=1
)
with mlflow.start_run(run_name='gb_hyperopt') as run:
# Use hyperopt to find the parameters yielding the highest AUC
best_params = fmin(
fn=train_model,
space=search_space,
algo=tpe.suggest,
max_evals=32,
trials=spark_trials)
Passo 9. Encontre o melhor modelo e registre-o no Catálogo Unity
O código a seguir identifica a execução que produziu os melhores resultados, conforme medido pela área sob a curva ROC:
# Sort runs by their test auc. In case of ties, use the most recent run.
best_run = mlflow.search_runs(
order_by=['metrics.test_auc DESC', 'start_time DESC'],
max_results=10,
).iloc[0]
print('Best Run')
print('AUC: {}'.format(best_run["metrics.test_auc"]))
print('Num Estimators: {}'.format(best_run["params.n_estimators"]))
print('Max Depth: {}'.format(best_run["params.max_depth"]))
print('Learning Rate: {}'.format(best_run["params.learning_rate"]))
Usando o run_id que você identificou para o melhor modelo, o código a seguir registra esse modelo no Unity Catalog.
model_uri = 'runs:/{run_id}/model'.format(
run_id=best_run.run_id
)
mlflow.register_model(model_uri, f"{CATALOG_NAME}.{SCHEMA_NAME}.wine_quality_model")
Passo 10. Implantar o modelo na produção
Quando estiver pronto para servir e implantar seus modelos, você poderá fazê-lo usando a interface do usuário de serviço em seu espaço de trabalho do Azure Databricks.
- Consulte Criar pontos de extremidade de serviço de modelo personalizado.
- Consulte Pontos de extremidade de serviço de consulta para modelos personalizados.
Exemplo de bloco de anotações: Criar um modelo de classificação
Use o bloco de anotações a seguir para executar as etapas neste artigo. Para obter instruções sobre como importar um bloco de anotações para um espaço de trabalho do Azure Databricks, consulte Importar um bloco de anotações.
Crie seu primeiro modelo de aprendizado de máquina com o Databricks
Mais informações
O Databricks fornece uma plataforma única que atende a todas as etapas do desenvolvimento e implantação de ML, desde dados brutos até tabelas de inferência que salvam todas as solicitações e respostas de um modelo atendido. Cientistas de dados, engenheiros de dados, engenheiros de ML e DevOps podem fazer seus trabalhos usando o mesmo conjunto de ferramentas e uma única fonte de verdade para os dados.
Para saber mais, consulte o seguinte:
- Tutoriais de aprendizado de máquina e IA
- Visão geral do aprendizado de máquina e IA no Databricks
- Visão geral do treinamento de modelos de aprendizado de máquina e IA no Databricks
- MLflow para ciclo de vida de modelos de ML