Nota
O acesso a esta página requer autorização. Podes tentar iniciar sessão ou mudar de diretório.
O acesso a esta página requer autorização. Podes tentar mudar de diretório.
Este artigo descreve como desenvolver um script de treinamento usando um bloco de anotações em uma estação de trabalho na nuvem do Azure Machine Learning. O tutorial aborda as etapas básicas que você precisa para começar:
- Instale e configure a estação de trabalho na nuvem. Sua estação de trabalho na nuvem é alimentada por uma instância de computação do Azure Machine Learning, que é pré-configurada com ambientes para dar suporte às suas necessidades de desenvolvimento de modelo.
- Use ambientes de desenvolvimento baseados em nuvem.
- Use o MLflow para acompanhar as métricas do seu modelo.
Pré-requisitos
Para usar o Azure Machine Learning, você precisa de um espaço de trabalho. Se você não tiver um, conclua Criar recursos necessários para começar a criar um espaço de trabalho e saiba mais sobre como usá-lo.
Importante
Se o seu espaço de trabalho do Azure Machine Learning estiver configurado com uma rede virtual gerenciada, talvez seja necessário adicionar regras de saída para permitir o acesso aos repositórios públicos de pacotes Python. Para obter mais informações, consulte Cenário: acessar pacotes públicos de aprendizado de máquina.
Criar ou iniciar recursos de computação
Você pode criar recursos de computação na seção Computação em seu espaço de trabalho. Uma instância de computação é uma estação de trabalho baseada na nuvem que é totalmente gerida pelo Azure Machine Learning. Esta série de tutoriais usa uma instância de computação. Você também pode usá-lo para executar seu próprio código e para desenvolver e testar modelos.
- Entre no estúdio do Azure Machine Learning.
- Selecione seu espaço de trabalho, se ainda não estiver aberto.
- No painel esquerdo, selecione Computar.
- Se você não tiver uma instância de computação, verá Novo no meio da página. Selecione Novo e preencha o formulário. Você pode usar todos os padrões.
- Se você tiver uma instância de computação, selecione-a na lista. Se estiver parado, selecione Iniciar.
Abrir código do Visual Studio (VS Code)
Depois de ter uma instância de computação em execução, você pode acessá-la de várias maneiras. Este tutorial descreve como usar a instância de computação do Visual Studio Code. O Visual Studio Code fornece um ambiente de desenvolvimento integrado (IDE) completo para a criação de instâncias de computação.
Na lista de instâncias de computação, selecione o link VS Code (Web) ou VS Code (Desktop) para a instância de computação que você deseja usar. Se escolher VS Code (Desktop), poderá ver uma mensagem a perguntar se pretende abrir a aplicação.

Esta instância do Visual Studio Code está anexada à sua instância de computação e ao seu sistema de arquivos de espaço de trabalho. Mesmo que o abra no ambiente de trabalho, os ficheiros que vê são ficheiros na sua área de trabalho.
Configurar um novo ambiente para prototipagem
Para que o script seja executado, você precisa estar trabalhando em um ambiente configurado com as dependências e bibliotecas esperadas pelo código. Esta seção ajuda você a criar um ambiente adaptado ao seu código. Para criar o novo kernel Jupyter ao qual seu notebook se conecta, use um arquivo YAML que define as dependências.
Carregue um ficheiro.
Os arquivos carregados são armazenados em um compartilhamento de arquivos do Azure e esses arquivos são montados em cada instância de computação e compartilhados no espaço de trabalho.
Vá para azureml-examples/tutorials/get-started-notebooks/workstation_env.yml.
Transfira o ficheiro de ambiente Conda workstation_env.yml para o seu computador selecionando o botão de reticências (...) no canto superior direito da página e, em seguida, selecionando Transferir.
Arraste o arquivo do seu computador para a janela Visual Studio Code. O ficheiro é carregado para a sua área de trabalho.
Mova o ficheiro para a pasta de nome de utilizador.
Selecione o arquivo para visualizá-lo. Analise as dependências que especifica. Você deve ver algo assim:
name: workstation_env # This file serves as an example - you can update packages or versions to fit your use case dependencies: - python=3.8 - pip=21.2.4 - scikit-learn=0.24.2 - scipy=1.7.1 - pandas>=1.1,<1.2 - pip: - mlflow-skinny - azureml-mlflow - psutil>=5.8,<5.9 - ipykernel~=6.0 - matplotlibCrie um kernel.
Agora use o terminal para criar um novo kernel Jupyter baseado no arquivo workstation_env.yml .
- No menu na parte superior do Visual Studio Code, selecione Terminal > New Terminal.

Veja os seus ambientes Conda atuais. O ambiente ativo está marcado com um asterisco (*).
conda env listUse
cdpara navegar até a pasta onde você carregou o arquivo workstation_env.yml . Por exemplo, se você o carregou para sua pasta de usuário, use este comando:cd Users/myusernameCertifique-se de workstation_env.yml está na pasta.
lsCrie o ambiente com base no arquivo Conda fornecido. Leva alguns minutos para configurar o ambiente.
conda env create -f workstation_env.ymlAtive o novo ambiente.
conda activate workstation_envNota
Se vir CommandNotFoundError, siga as instruções para executar
conda init bash, feche o terminal e, em seguida, abra um novo. Em seguida, tente oconda activate workstation_envcomando novamente.Verifique se o ambiente correto está ativo, procurando novamente o ambiente marcado com um *.
conda env listCrie um novo kernel Jupyter baseado no seu ambiente ativo.
python -m ipykernel install --user --name workstation_env --display-name "Tutorial Workstation Env"Feche a janela do terminal.
Agora você tem um novo kernel. Em seguida, você abrirá um bloco de anotações e usará esse kernel.
Criar um bloco de notas
- No menu na parte superior do Visual Studio Code, selecione Arquivo > Novo Arquivo.
- Nomeie seu novo arquivo develop-tutorial.ipynb (ou use outro nome). Certifique-se de usar a extensão .ipynb .
Definir o kernel
- No canto superior direito do novo ficheiro, selecione Selecionar Núcleo.
- Selecione Instância de computação do Azure ML (computeinstance-name).
- Selecione o kernel que você criou: Tutorial Workstation Env. Se você não vir o kernel, selecione o botão de atualização acima da lista.
Desenvolver um script de treinamento
Nesta seção, desenvolve-se um script de treinamento em Python que prevê o incumprimento de pagamentos de cartão de crédito usando os conjuntos de dados de teste e de treino preparados do conjunto de dados UCI.
Este código usa sklearn para o treino e o MLflow para registrar métricas.
Comece com o código que importa os pacotes e bibliotecas que você usará no script de treinamento.
import os import argparse import pandas as pd import mlflow import mlflow.sklearn from sklearn.ensemble import GradientBoostingClassifier from sklearn.metrics import classification_report from sklearn.model_selection import train_test_splitEm seguida, carregue e processe os dados para o experimento. Neste tutorial, você lê os dados de um arquivo na internet.
# load the data credit_df = pd.read_csv( "https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csv", header=1, index_col=0, ) train_df, test_df = train_test_split( credit_df, test_size=0.25, )Prepare os dados para treinamento.
# Extracting the label column y_train = train_df.pop("default payment next month") # convert the dataframe values to array X_train = train_df.values # Extracting the label column y_test = test_df.pop("default payment next month") # convert the dataframe values to array X_test = test_df.valuesAdicione código para iniciar o registro automático com MLflow para que você possa acompanhar as métricas e os resultados. Com a natureza iterativa do desenvolvimento de modelos, o MLflow ajuda a registrar parâmetros e resultados do modelo. Consulte diferentes execuções para comparar e entender o desempenho do seu modelo. Os logs também fornecem contexto para quando você estiver pronto para passar da fase de desenvolvimento para a fase de treinamento de seus fluxos de trabalho no Azure Machine Learning.
# set name for logging mlflow.set_experiment("Develop on cloud tutorial") # enable autologging with MLflow mlflow.sklearn.autolog()Treine um modelo.
# Train Gradient Boosting Classifier print(f"Training with data of shape {X_train.shape}") mlflow.start_run() clf = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1) clf.fit(X_train, y_train) y_pred = clf.predict(X_test) print(classification_report(y_test, y_pred)) # Stop logging for this model mlflow.end_run()Nota
Você pode ignorar os avisos MLflow. Os resultados que você precisa ainda serão rastreados.
Selecione Executar tudo acima do código.
Iterar
Agora que você tem resultados de modelo, altere algo e execute o modelo novamente. Por exemplo, tente uma técnica de classificação diferente:
# Train AdaBoost Classifier
from sklearn.ensemble import AdaBoostClassifier
print(f"Training with data of shape {X_train.shape}")
mlflow.start_run()
ada = AdaBoostClassifier()
ada.fit(X_train, y_train)
y_pred = ada.predict(X_test)
print(classification_report(y_test, y_pred))
# Stop logging for this model
mlflow.end_run()Nota
Você pode ignorar os avisos MLflow. Os resultados que você precisa ainda serão rastreados.
Selecione Executar tudo para executar o modelo.
Examinar os resultados
Agora que você já experimentou dois modelos diferentes, use os resultados rastreados pelo MLFfow para decidir qual modelo é melhor. Você pode fazer referência a métricas como precisão ou outros indicadores que são mais importantes para seus cenários. Você pode revisar esses resultados com mais detalhes observando os trabalhos criados pelo MLflow.
Retorne ao seu espaço de trabalho no estúdio do Azure Machine Learning.
No painel esquerdo, selecione Trabalhos.

Selecione Tutorial Desenvolvimento na nuvem.
Há dois trabalhos mostrados, um para cada um dos modelos que você tentou. Os nomes são gerados automaticamente. Se você quiser renomear o trabalho, passe o mouse sobre o nome e selecione o botão de lápis ao lado dele.
Selecione o link para o primeiro trabalho. O nome aparece na parte superior da página. Você também pode renomeá-lo aqui usando o botão de lápis.
A página mostra detalhes do trabalho, como propriedades, saídas, tags e parâmetros. Em Tags, você verá o estimator_name, que descreve o tipo de modelo.
Selecione a guia Métricas para exibir as métricas que foram registradas pelo MLflow. (Seus resultados serão diferentes porque você tem um conjunto de treinamento diferente.)
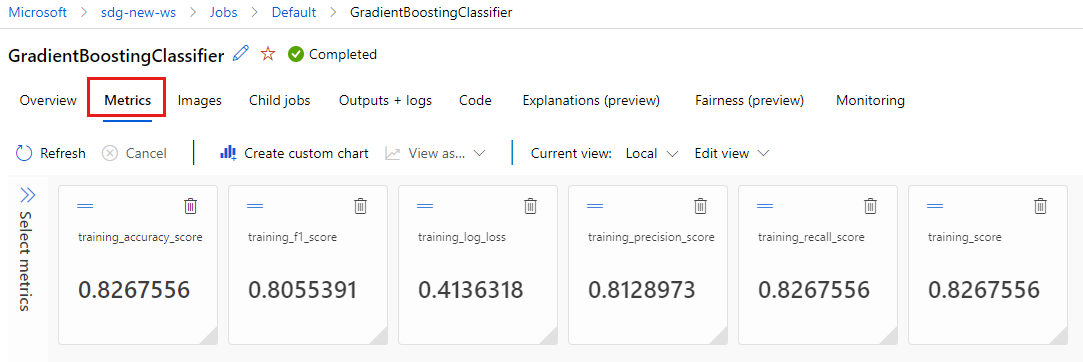
Selecione a guia Imagens para visualizar as imagens geradas pelo MLflow.

Volte e revise as métricas e imagens do outro modelo.

Criar um script Python
Agora você criará um script Python a partir do seu bloco de anotações para treinamento de modelos.
No Visual Studio Code, clique com o botão direito do mouse no nome do arquivo do bloco de anotações e selecione Importar Bloco de Anotações para Script.
Selecione Salvar arquivo > para salvar o novo arquivo de script. Chamem-lhe train.py.
Examine o arquivo e exclua o código que você não deseja no script de treinamento. Por exemplo, mantenha o código do modelo que você deseja usar e exclua o código do modelo que você não deseja usar.
- Certifique-se de manter o código que inicia o registro automático (
mlflow.sklearn.autolog()). - Quando você executa o script Python interativamente (como está fazendo aqui), você pode manter a linha que define o nome do experimento (
mlflow.set_experiment("Develop on cloud tutorial")). Ou você pode dar a ele um nome diferente para vê-lo como uma entrada diferente na seção Trabalhos . Mas quando você prepara o script para um trabalho de treinamento, essa linha não se aplica e deve ser omitida: a definição de trabalho inclui o nome do experimento. - Quando você treina um único modelo, as linhas para iniciar e terminar uma corrida (
mlflow.start_run()emlflow.end_run()) não são necessárias (elas não têm efeito), mas você pode deixá-las dentro.
- Certifique-se de manter o código que inicia o registro automático (
Quando terminar as edições, salve o arquivo.
Agora você tem um script Python para usar para treinar seu modelo preferido.
Execute o script Python
Por enquanto, você está executando esse código em sua instância de computação, que é seu ambiente de desenvolvimento do Azure Machine Learning. Tutorial: Treinar um modelo mostra como executar um script de treinamento de forma mais escalável em recursos de computação mais poderosos.
Selecione o ambiente que você criou anteriormente neste tutorial como sua versão Python (workstations_env). No canto inferior direito do bloco de anotações, você verá o nome do ambiente. Selecione-o e, em seguida, selecione o ambiente na parte superior do Visual Studio Code.
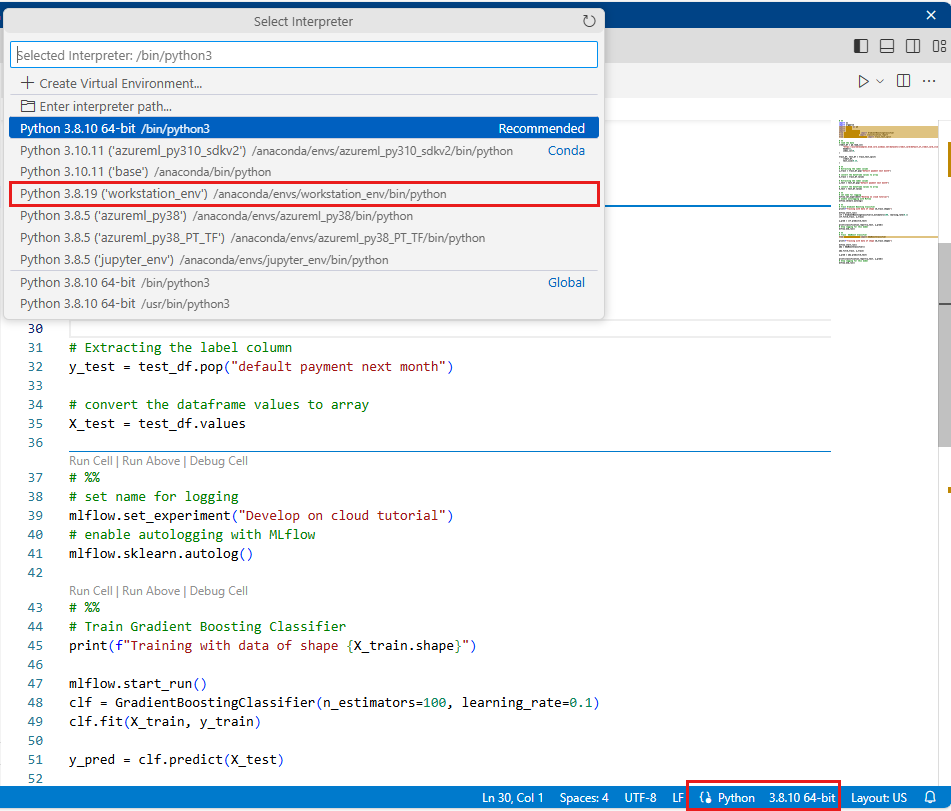
Execute o script Python selecionando o botão Executar tudo acima do código.


Nota
Você pode ignorar os avisos MLflow. Você ainda obterá todas as métricas e imagens do registro automático.
Examine os resultados do script
Volte para Trabalhos em seu espaço de trabalho no estúdio de Aprendizado de Máquina do Azure para ver os resultados do seu script de treinamento. Lembre-se de que os dados de treinamento mudam a cada divisão, portanto, os resultados diferem entre as corridas.
Clean up resources (Limpar recursos)
Se você planeja continuar com outros tutoriais, pule para Próximas etapas.
Pare a instância de computação
Se você não vai usá-lo agora, pare a instância de computação:
- No estúdio, no painel esquerdo, selecione Computar.
- Na parte superior da página, selecione Instâncias de computação.
- Na lista, selecione a instância de computação.
- Na parte superior da página, selecione Parar.
Eliminar todos os recursos
Importante
Os recursos que você criou podem ser usados como pré-requisitos para outros tutoriais e artigos de instruções do Azure Machine Learning.
Se você não planeja usar nenhum dos recursos que criou, exclua-os para não incorrer em cobranças:
No portal do Azure, na caixa de pesquisa, insira Grupos de recursos e selecione-o nos resultados.
Na lista, selecione o grupo de recursos que você criou.
Na página Visão geral, selecione Excluir grupo de recursos.

Insira o nome do grupo de recursos. Em seguida, selecione Eliminar.
Próximos passos
Veja estes recursos para saber mais:
- Artefatos e modelos no MLflow
- Using Git with Azure Machine Learning (Utilizar o Git com o Azure Machine Learning)
- Executando blocos de anotações Jupyter em seu espaço de trabalho
- Trabalhando com um terminal de instância de computação em seu espaço de trabalho
- Gerir sessões de blocos de notas e terminais
Este tutorial mostra as primeiras etapas da criação de um modelo, prototipando na mesma máquina onde o código reside. Para seu treinamento de produção, saiba como usar esse script de treinamento em recursos de computação remota mais poderosos: