Nota
O acesso a esta página requer autorização. Podes tentar iniciar sessão ou mudar de diretório.
O acesso a esta página requer autorização. Podes tentar mudar de diretório.
Saiba como enriquecer facilmente seus dados em pools SQL dedicados com modelos preditivos de aprendizado de máquina. Os modelos que seus cientistas de dados criam agora são facilmente acessíveis aos profissionais de dados para análise preditiva. Um profissional de dados no Azure Synapse Analytics pode simplesmente selecionar um modelo do registro do modelo do Azure Machine Learning para implantação nos pools SQL do Azure Synapse e iniciar previsões para enriquecer os dados.
Neste tutorial, você aprenderá a:
- Preparar um modelo de machine learning preditivo e registar o modelo no registo de modelos do Azure Machine Learning.
- Utilizar o assistente de classificação do SQL para iniciar predições num conjunto de SQL dedicado.
Se não tiver uma subscrição do Azure, crie uma conta gratuita antes de começar.
Pré-requisitos
- Espaço de trabalho do Azure Synapse Analytics com uma conta de armazenamento do Azure Data Lake Storage Gen2 configurada como o armazenamento padrão. Você precisa ser o Storage Blob Data Contributor do sistema de arquivos Data Lake Storage Gen2 com o qual trabalha.
- Pool SQL dedicado em seu espaço de trabalho do Azure Synapse Analytics. Para obter detalhes, consulte Criar um pool SQL dedicado.
- Serviço vinculado do Azure Machine Learning no seu espaço de trabalho do Azure Synapse Analytics. Para obter detalhes, consulte Criar um serviço vinculado do Azure Machine Learning no Azure Synapse.
Entre no portal do Azure
Inicie sessão no portal Azure.
Treinar um modelo no Azure Machine Learning
Antes de começar, verifique se a sua versão do sklearn é 0.20.3.
Antes de executar todas as células do bloco de anotações, verifique se a instância de computação está em execução.

Vá para seu espaço de trabalho do Azure Machine Learning.
Baixar Predict NYC Taxi Tips.ipynb.
Abra o espaço de trabalho do Azure Machine Learning no Azure Machine Learning Studio.
Vá para Blocos de Anotações>Carregar arquivos. Em seguida, selecione o arquivo Predict NYC Taxi Tips.ipynb que você baixou e carregue-o.
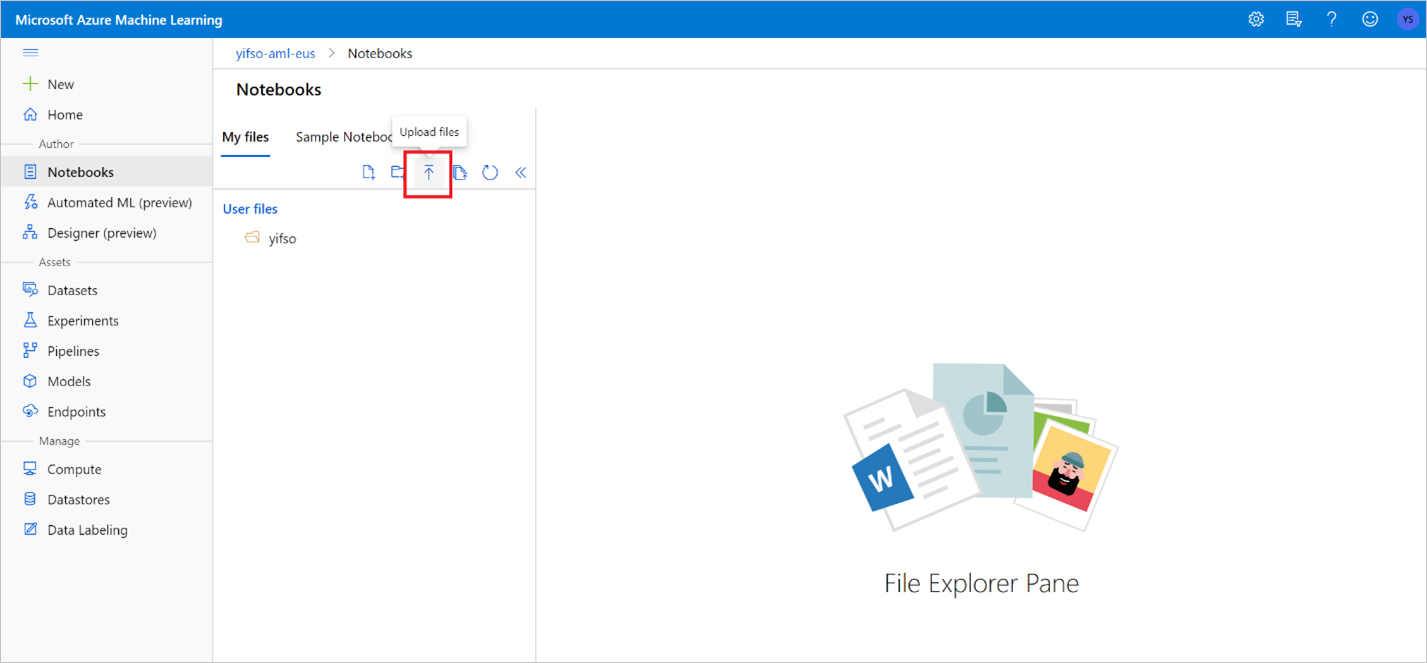
Depois que o bloco de anotações for carregado e aberto, selecione Executar todas as células.
Uma das células pode falhar e pedir que você se autentique no Azure. Observe isso nas saídas da célula e autentique-se em seu navegador seguindo o link e inserindo o código. Em seguida, execute novamente o notebook.
O notebook treinará um modelo ONNX e o registrará no MLflow. Vá para Modelos para verificar se o novo modelo está registrado corretamente.
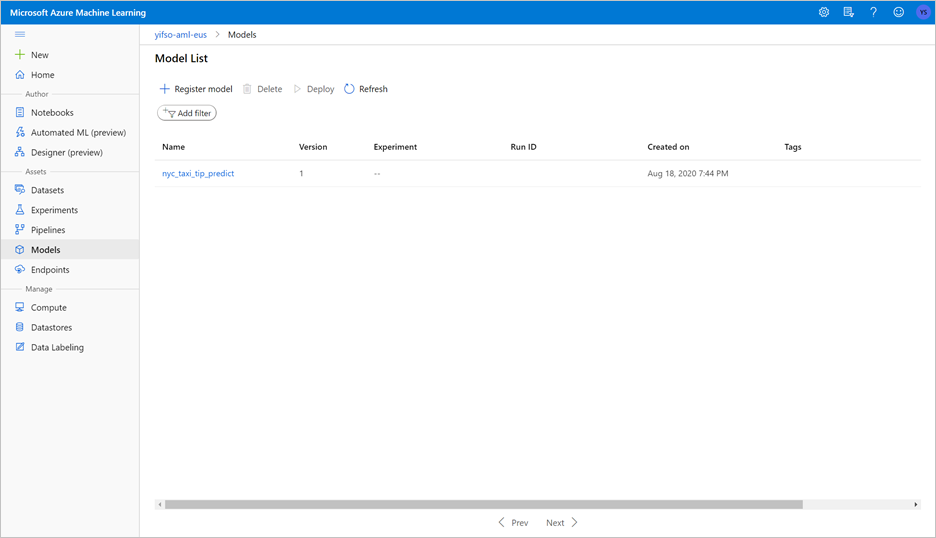
Ao executar o notebook, os dados de teste também serão exportados para um ficheiro CSV. Transfira o ficheiro CSV para o seu sistema local. Mais tarde, você importará o arquivo CSV para um pool SQL dedicado e usará os dados para testar o modelo.
O arquivo CSV é criado na mesma pasta que o arquivo do bloco de anotações. Selecione Atualizar no Explorador de Arquivos se não aparecer imediatamente.
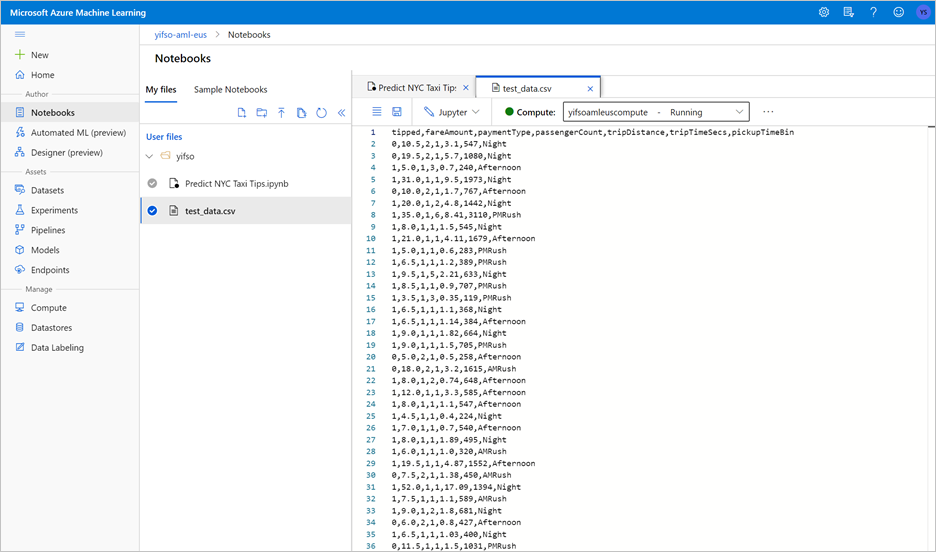
Inicie previsões com o assistente de avaliação SQL
Abra o espaço de trabalho do Azure Synapse com o Synapse Studio.
Vá para Dados>Vinculadas>Contas de Armazenamento. Carregue
test_data.csvpara a conta de armazenamento padrão.
Vá para Desenvolver>scripts SQL. Crie um novo script SQL para carregar
test_data.csvem seu pool SQL dedicado.Observação
Atualize o URL do arquivo neste script antes de executá-lo.
IF NOT EXISTS (SELECT * FROM sys.objects WHERE NAME = 'nyc_taxi' AND TYPE = 'U') CREATE TABLE dbo.nyc_taxi ( tipped int, fareAmount float, paymentType int, passengerCount int, tripDistance float, tripTimeSecs bigint, pickupTimeBin nvarchar(30) ) WITH ( DISTRIBUTION = ROUND_ROBIN, CLUSTERED COLUMNSTORE INDEX ) GO COPY INTO dbo.nyc_taxi (tipped 1, fareAmount 2, paymentType 3, passengerCount 4, tripDistance 5, tripTimeSecs 6, pickupTimeBin 7) FROM '<URL to linked storage account>/test_data.csv' WITH ( FILE_TYPE = 'CSV', ROWTERMINATOR='0x0A', FIELDQUOTE = '"', FIELDTERMINATOR = ',', FIRSTROW = 2 ) GO SELECT TOP 100 * FROM nyc_taxi GO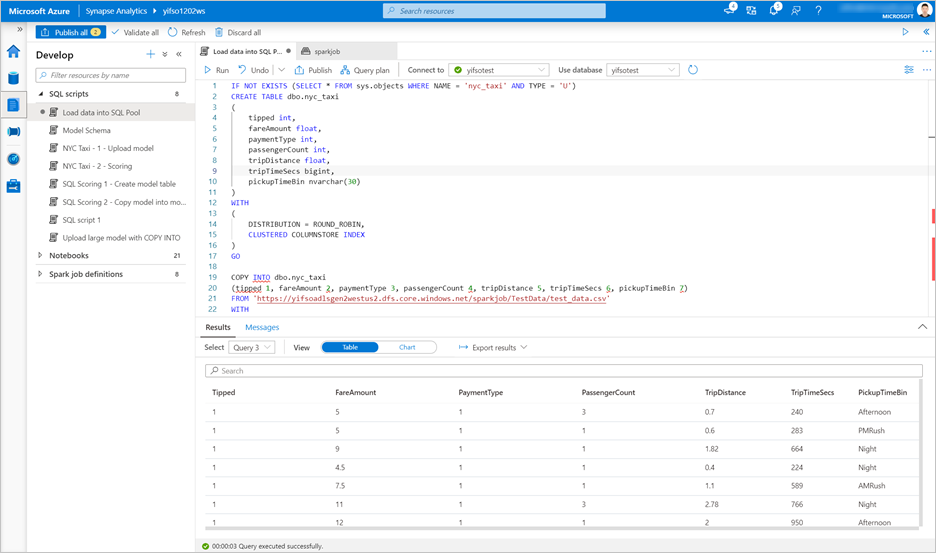
Vá para Data>Workspace. Abra o assistente de pontuação SQL clicando com o botão direito do mouse na tabela de pool SQL dedicada. Selecione Machine Learning>Prever com um modelo.
Observação
A opção de aprendizado de máquina não aparece a menos que você tenha um serviço vinculado criado para o Azure Machine Learning. (Consulte Pré-requisitos no início deste tutorial.)
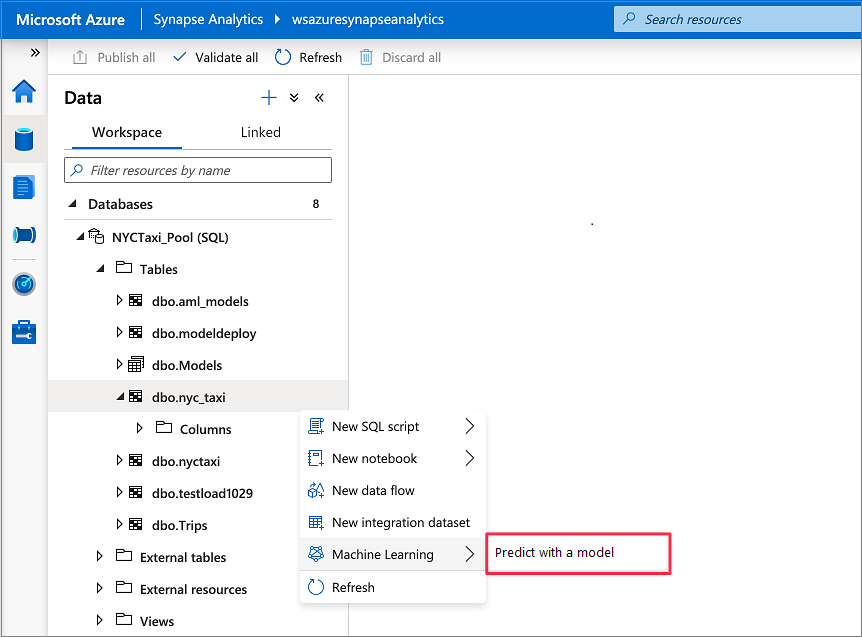
Na caixa suspensa, selecione um espaço de trabalho vinculado ao Azure Machine Learning. Esta etapa carrega uma lista de modelos de aprendizado de máquina do registro de modelo do espaço de trabalho do Azure Machine Learning escolhido. Atualmente, apenas modelos ONNX são suportados, portanto, esta etapa exibirá apenas modelos ONNX.
Selecione o modelo que acabou de treinar e, em seguida, selecione Continuar.
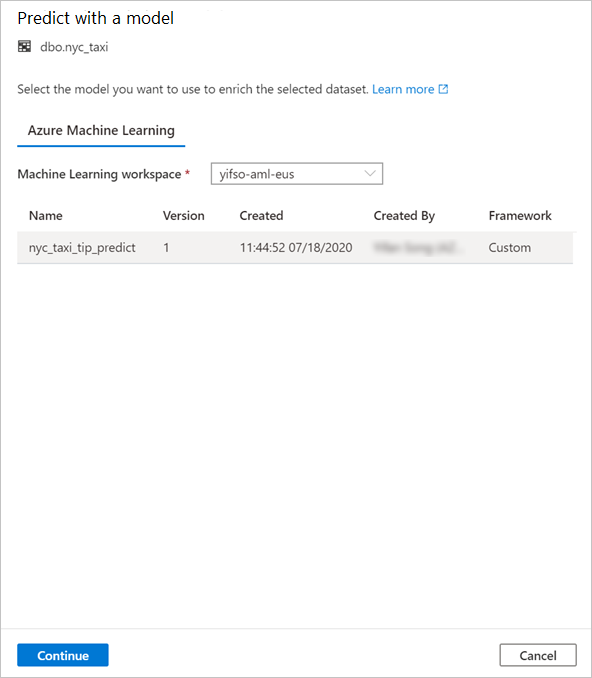
Mapeie as colunas da tabela para as entradas do modelo e especifique as saídas do modelo. Se o modelo for salvo no formato MLflow e a assinatura do modelo for preenchida, o mapeamento será feito automaticamente para você usando uma lógica baseada na semelhança de nomes. A interface também suporta mapeamento manual.
Selecione Continuar.
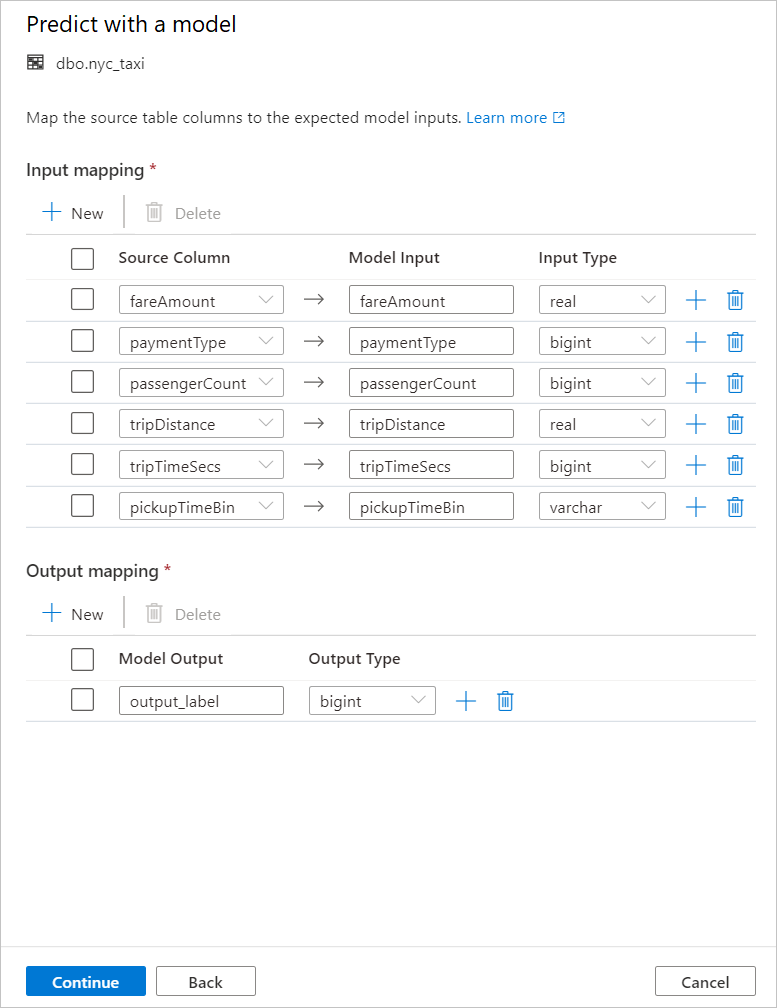
O código T-SQL gerado é encapsulado dentro de um procedimento armazenado. É por isso que você precisa fornecer um nome de procedimento armazenado. O binário do modelo, incluindo metadados (versão, descrição e outras informações), será copiado fisicamente do Aprendizado de Máquina do Azure para uma tabela de pool SQL dedicada. Portanto, você precisa especificar em qual tabela salvar o modelo.
Você pode escolher Tabela existente ou Criar nova. Quando terminar, selecione Implantar modelo + script aberto para implantar o modelo e gerar um script de previsão T-SQL.
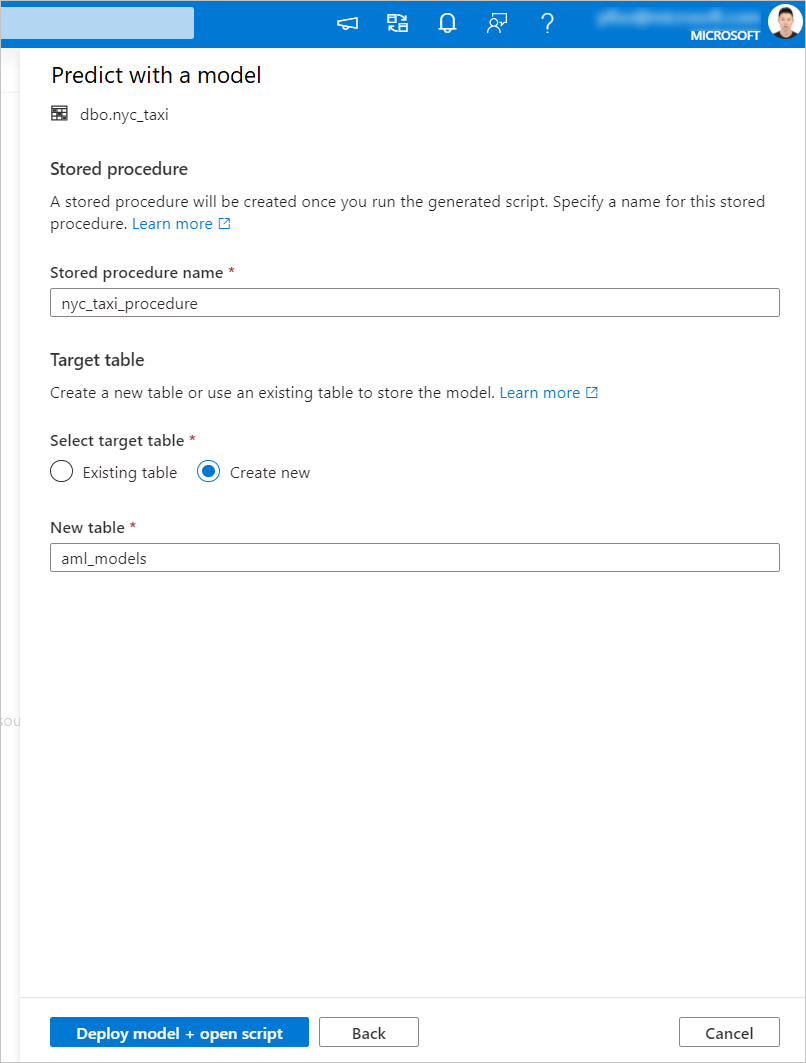
Depois que o script for gerado, selecione Executar para executar a pontuação e obter previsões.
