Nota
O acesso a esta página requer autorização. Podes tentar iniciar sessão ou mudar de diretório.
O acesso a esta página requer autorização. Podes tentar mudar de diretório.
O tempo de execução do Fabric oferece uma integração perfeita com o Azure. Ele fornece um ambiente sofisticado para projetos de engenharia de dados e ciência de dados que usam o Apache Spark. Este artigo fornece uma visão geral dos recursos e componentes essenciais do Fabric Runtime 1.3, o mais recente tempo de execução para cálculos de big data.
O Microsoft Fabric Runtime 1.3 é a versão mais recente do tempo de execução do GA e incorpora os seguintes componentes e atualizações projetados para aprimorar seus recursos de processamento de dados:
Apache Spark 3,5
Sistema Operacional: Mariner 2.0
Java: 11
Escala: 2.12.17
Píton: 3.11
Lago Delta: 3.2
R: 4.4.1
Gorjeta
O Fabric Runtime 1.3 inclui suporte para o Native Execution Engine, que pode melhorar significativamente o desempenho sem mais custos. Para habilitar o mecanismo de execução nativo em todos os trabalhos e blocos de anotações em seu ambiente, navegue até as configurações do ambiente, selecione Computação do Spark, vá para a guia Aceleração e marque Habilitar mecanismo de execução nativo. Depois de salvar e publicar, essa configuração é aplicada em todo o ambiente, para que todos os novos trabalhos e blocos de anotações herdem e se beneficiem automaticamente dos recursos de desempenho aprimorados.
Integrar o Runtime 1.3
Use as instruções a seguir para integrar o tempo de execução 1.3 em seu espaço de trabalho e usar seus novos recursos:
Navegue até a guia Configurações do espaço de trabalho dentro do espaço de trabalho Malha.
Vá para a guia Engenharia de Dados/Ciência e selecione Configurações do Spark.
Selecione o separador Ambiente.
Em Versões de tempo de execução, expanda a lista suspensa.
Selecione 1.3 (Spark 3.5, Delta 3.2) e salve suas alterações. Esta ação define 1.3 como o tempo de execução padrão para seu espaço de trabalho.
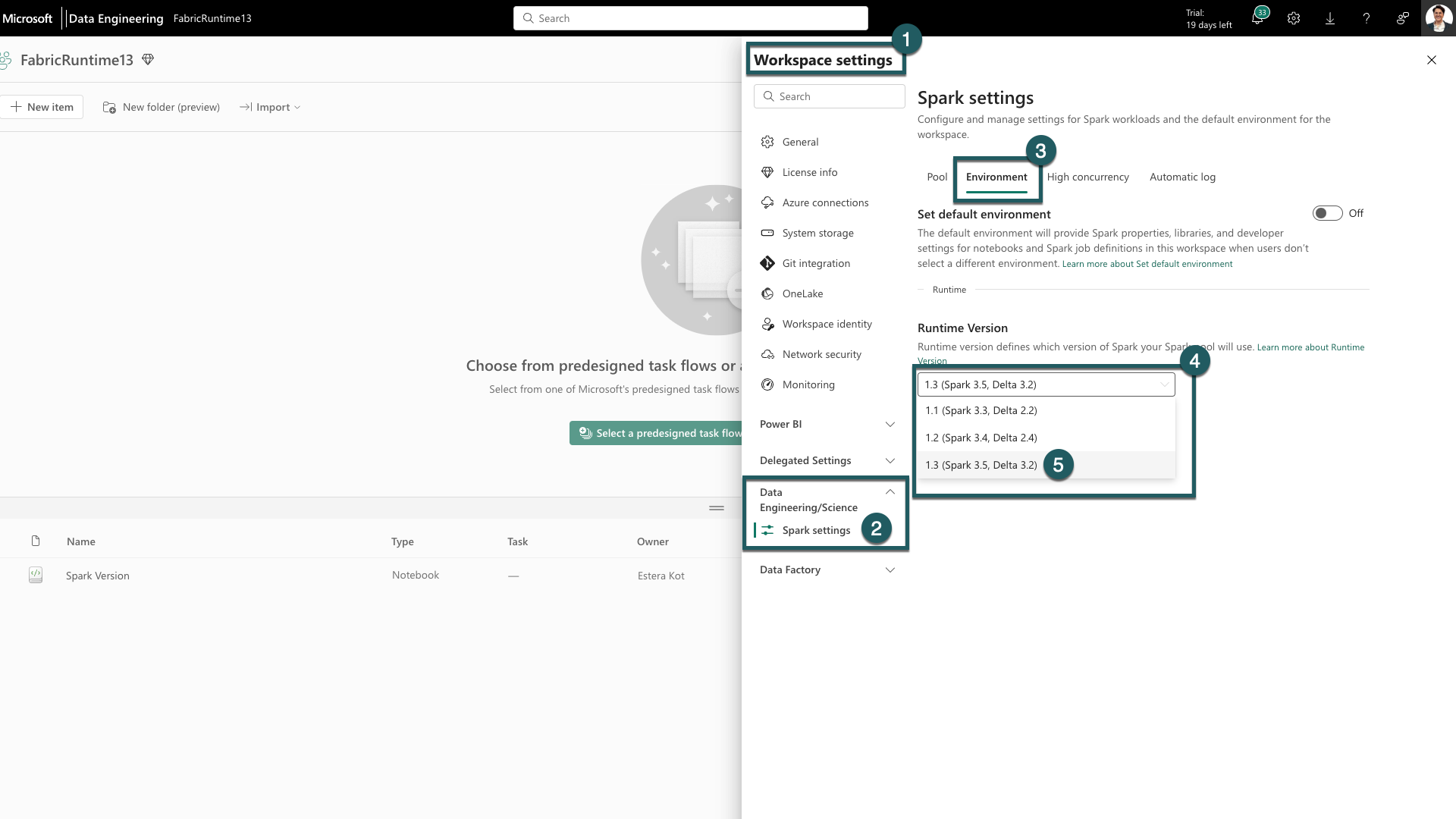

Agora você pode começar a trabalhar com as mais recentes melhorias e funcionalidades introduzidas no tempo de execução do Fabric 1.3 (Spark 3.5 e Delta Lake 3.2).
Saiba mais sobre o Apache Spark 3.5
Apache Spark 3.5.0 é a sexta versão da série 3.x. Esta versão é um produto de extensa colaboração dentro da comunidade de código aberto, abordando mais de 1.300 problemas conforme registrado em Jira.
Nesta versão, há uma atualização na compatibilidade para streaming estruturado. Além disso, esta versão amplia a funcionalidade dentro do PySpark e SQL. Ele adiciona recursos como a cláusula de identificador SQL, argumentos nomeados em chamadas de função SQL e a inclusão de funções SQL para agregações aproximadas HyperLogLog.
Outros novos recursos também incluem funções de tabela definidas pelo usuário do Python, a simplificação do treinamento distribuído via DeepSpeed e novos recursos de streaming estruturado, como propagação de marca d'água e a operação dropDuplicatesWithinWatermark .
Você pode conferir a lista completa e as alterações detalhadas aqui: Spark Release 3.5.0.
Saiba mais sobre o Delta Spark
O Delta Lake 3.2 marca um compromisso coletivo de tornar o Delta Lake interoperável entre formatos, mais fácil de trabalhar e mais eficiente. Delta Spark 3.2 é construído sobre o Apache Spark™ 3.5. O artefato Delta Spark maven é renomeado de delta-core para delta-spark.
Pode consultar a lista completa e as alterações detalhadas aqui: https://docs.delta.io/index.html.
Componentes e bibliotecas
Para obter informações atualizadas, uma lista detalhada de alterações e notas de versão específicas para tempos de execução do Fabric, verifique e assine as versões e atualizações do Spark Runtimes.
Observação
O EventHubConnector foi preterido no Fabric Runtime 1.3 (Spark 3.5) e será removido de versões futuras do Fabric Runtime. Os clientes são incentivados a usar o Kafka Spark Connector, pois o Event Hubs já é compatível com Kafka. Pode encontrar mais informações sobre como usar o Kafka Spark Connector com Event Hubs aqui: Event Hubs Kafka Spark Tutorial
Conteúdos relacionados
- Leia sobre Apache Spark Runtimes in Fabric - Visão geral, versionamento, suporte a vários tempos de execução e atualização do protocolo Delta Lake
- Guia de migração do Spark Core
- Guias de migração SQL, Datasets e DataFrame
- Guia de migração do Streaming Estruturado
- Guia de migração MLlib (Machine Learning)
- Guia de migração do PySpark (Python on Spark)
- Guia de migração do SparkR (R on Spark)