Nota
O acesso a esta página requer autorização. Podes tentar iniciar sessão ou mudar de diretório.
O acesso a esta página requer autorização. Podes tentar mudar de diretório.
Observação
O Fabric Runtime 2.0 encontra-se atualmente numa fase experimental de pré-visualização. Para mais informações, consulte as limitações e notas.
O Fabric Runtime proporciona uma integração fluida dentro do ecossistema Microsoft Fabric, proporcionando um ambiente robusto para projetos de engenharia de dados e ciência de dados alimentados pelo Apache Spark.
Este artigo apresenta o Fabric Runtime 2.0 Experimental (Preview), o mais recente runtime concebido para cálculos de big data no Microsoft Fabric. Destaca as principais funcionalidades e componentes que tornam este lançamento um avanço significativo para análises escaláveis e cargas de trabalho avançadas.
O Fabric Runtime 2.0 incorpora os seguintes componentes e atualizações concebidos para melhorar as suas capacidades de processamento de dados:
- Apache Spark 4.0
- Sistema operativo: Azure Linux 3.0 (Mariner 3.0)
- Java: 21
- Scala: 2.13
- Python: 3.12
- Delta Lake: 4.0
Ativar o Runtime 2.0
Podes ativar o Runtime 2.0 tanto ao nível do workspace como ao nível do item do ambiente. Usa a definição workspace para aplicar o Runtime 2.0 como padrão para todas as cargas de trabalho do Spark no teu espaço de trabalho. Alternativamente, crie um item de Ambiente com Runtime 2.0 para usar com cadernos específicos ou definições de trabalhos do Spark, que substitui o padrão do espaço de trabalho.
Ativar o Runtime 2.0 nas definições do Workspace
Para definir o Runtime 2.0 como padrão para todo o seu espaço de trabalho:
Navegue até a guia Configurações do espaço de trabalho dentro do espaço de trabalho Malha.

Vai ao separador de Engenharia/Ciência de Dados e seleciona as definições do Spark.
Selecione o separador Ambiente.
No menu pendente da versão Runtime, selecione 2.0 Experimental (Spark 4.0, Delta 4.0) e guarde as suas alterações. Esta ação define o Runtime 2.0 como o tempo de execução padrão para o seu espaço de trabalho.

Ativar o Tempo de Execução 2.0 num item de Ambiente
Para usar o Runtime 2.0 com notebooks específicos ou definições de funções Spark:
Crie um novo item de Ambiente ou abra um já existente.
No menu pendente Runtime, selecione 2.0 Experimental (Spark 4.0, Delta 4.0)
SaveePublishguarde as suas alterações.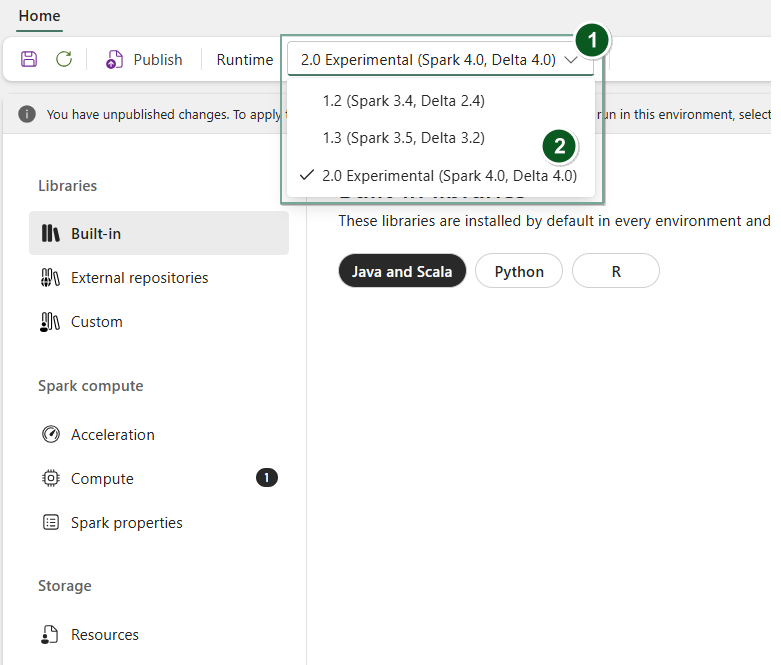
Importante
Pode demorar cerca de 2 a 5 minutos para as sessões do Spark 2.0 começarem, pois os pools iniciais não fazem parte do lançamento experimental inicial.
De seguida, pode usar este item Ambiente com o seu
NotebookouSpark Job Definition.

Agora pode começar a experimentar as mais recentes melhorias e funcionalidades introduzidas no Fabric Runtime 2.0 (Spark 4.0 e Delta Lake 4.0).
Pré-visualização Pública Experimental
A fase experimental de pré-visualização do runtime do Fabric 2.0 dá-lhe acesso antecipado a novas funcionalidades e APIs tanto do Spark 4.0 como do Delta Lake 4.0. A pré-visualização permite-lhe usar imediatamente as melhorias mais recentes baseadas no Spark, garantindo uma prontidão suave e uma transição para mudanças futuras, como as versões mais recentes em Java, Scala e Python.
Sugestão
Para obter informações atualizadas, uma lista detalhada de alterações e notas de versão específicas para tempos de execução do Fabric, verifique e assine as versões e atualizações do Spark Runtimes.
Limitações e Notas
O Fabric Runtime 2.0 encontra-se atualmente numa fase experimental de pré-visualização pública, concebido para que os utilizadores possam explorar e experimentar as funcionalidades e APIs mais recentes da Spark e Delta Lake nos ambientes de desenvolvimento ou teste. Embora esta versão ofereça acesso a funcionalidades essenciais, existem certas limitações:
Pode usar sessões Spark 4.0, escrever código em cadernos, agendar definições de trabalhos Spark e usar com PySpark, Scala e SQL Spark. No entanto, a linguagem R não é suportada nesta versão inicial.
Podes instalar bibliotecas diretamente no teu código com pip e conda. Podes definir as definições do Spark através das opções de %%configure nos cadernos e nas Definições de Trabalho do Spark (SJDs).
Pode ler e escrever no Lakehouse com Delta Lake 4.0, mas algumas funcionalidades avançadas, como V-order, escrita nativa em Parquet, autocompactação, otimização de escrita, low-shuffle merge, merge, evolução de esquemas e viagem no tempo, não estão incluídas nesta versão inicial.
O Spark Advisor está de momento indisponível. No entanto, ferramentas de monitorização como a interface Spark e os registos são suportadas nesta versão antecipada.
Funcionalidades como integrações de Data Science incluindo Copilot e conectores como Kusto, SQL Analytics, Cosmos DB e MySQL Java Connector não são atualmente suportadas nesta versão inicial. As bibliotecas de Ciência de Dados não são suportadas em ambientes PySpark. O PySpark só funciona com uma configuração básica do Conda, que inclui apenas o PySpark sem bibliotecas extra.
Integrações com item de ambiente e Visual Studio Code não são suportadas nesta versão inicial.
Não suporta a leitura e gravação de dados em contas Azure Storage General Purpose v2 (GPv2) com protocolos WASB ou ABFS.
Observação
Partilhe o seu feedback sobre o Fabric Runtime na plataforma Ideas. Certifica-te de mencionar a versão e a fase de lançamento a que te referes. Valorizamos o feedback da comunidade e priorizamos melhorias com base nos votos, garantindo que respondemos às necessidades dos utilizadores.
Destaques chave
Apache Spark 4.0
Apache Spark 4.0 marca um marco significativo como o lançamento inaugural da série 4.x, incorporando o esforço coletivo da vibrante comunidade open-source.
Nesta versão, o Spark SQL está significativamente enriquecido com novas funcionalidades poderosas concebidas para aumentar a expressividade e versatilidade para cargas de trabalho SQL, como suporte a tipos de dados VARIANT, funções definidas pelo utilizador SQL, variáveis de sessão, sintaxe de pipe e colação de strings. A PySpark demonstra dedicação contínua tanto à sua amplitude funcional como à experiência global dos programadores, trazendo uma API nativa de ploting, uma nova API de Fonte de Dados em Python, suporte para UDTFs em Python e perfilagem unificada para UDFs PySpark, juntamente com inúmeras outras melhorias. O Structured Streaming evolui com adições chave que proporcionam maior controlo e facilidade de depuração, nomeadamente a introdução da API de Estado Arbitrário v2 para uma gestão de estados mais flexível e da Fonte de Dados de Estado para facilitar a depuração.
Pode consultar a lista completa e as alterações detalhadas aqui: https://spark.apache.org/releases/spark-release-4-0-0.html.
Observação
No Spark 4.0, o SparkR está obsoleto e poderá ser removido numa versão futura.
Delta Lake 4.0
O Delta Lake 4.0 assinala um compromisso coletivo em tornar o Delta Lake interoperável em vários formatos, mais fácil de trabalhar e mais eficiente. O Delta 4.0 é um lançamento marcante repleto de novas funcionalidades poderosas, otimizações de desempenho e melhorias fundamentais para o futuro dos lagos de dados abertos.
Pode consultar a lista completa e as alterações detalhadas introduzidas com Delta Lake 3.3 e 4.0 aqui: https://github.com/delta-io/delta/releases/tag/v3.3.0. https://github.com/delta-io/delta/releases/tag/v4.0.0.
Importante
As funcionalidades específicas do Delta Lake 4.0 são experimentais e funcionam apenas em experiências Spark, como Cadernos e Definições de Funções Spark. Se precisares de usar as mesmas tabelas Delta Lake em várias cargas de trabalho do Microsoft Fabric, não atives essas funcionalidades. Para saber mais sobre quais as versões e funcionalidades dos protocolos são compatíveis em todas as experiências do Microsoft Fabric, leia interoperabilidade do formato de tabela Delta Lake.
Conteúdo relacionado
- Ambientes de Execução do Apache Spark no Fabric - Visão Geral, Versionamento e Suporte a Múltiplos Ambientes de Execução
- Guia de migração do Spark Core
- Guias de migração SQL, Datasets e DataFrame
- Guia de migração do Streaming Estruturado
- Guia de migração MLlib (Machine Learning)
- Guia de migração do PySpark (Python on Spark)
- Guia de migração do SparkR (R on Spark)